

IBM išleido „Granite 4.0 3B Vision“: naują „Vision“ kalbos modelį, skirtą įmonės klasės dokumentų duomenų išgavimui
IBM paskelbė apie išleidimą Granitas 4.0 3B Visionvizijos kalbos modelis (VLM), sukurtas…

Ar mažos kalbos modelis gali numatyti branduolio latenciją, atmintį ir modelio tikslumą iš kodo? Naujas regresijos kalbos modelis (RLM) sako taip
Kornelio ir „Google“ tyrėjai pristato vieningą regresijos…

„Deepseeek AI“ pristato kodą/O: naujas požiūris, kuris paverčia kodu pagrįstus samprotavimo modelius natūraliomis kalbos formatais, siekiant sustiprinti LLMS samprotavimo galimybes
Didelių kalbų modeliai (LLM) žymiai pažengė į gamtos kalbų apdorojimą, tačiau samprotavimai…

Prasideda jubiliejinės Lietuvių kalbos dienos: 2025-ųjų sostinė – Šiauliai!
Lietuvoje ir pasaulyje prasideda Lietuvių kalbos dienos, šiemet jau dešimtosios. Vasario ir…
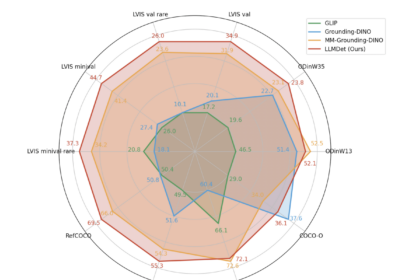
„LLMDET“: kiek dideli kalbos modeliai pagerina atvirojo balsavimo objekto aptikimą
Objekto „Object“ (OVD) atvirojo balsavimo objekto nustatymo (OVD) siekiama aptikti savavališkus objektus…

„Kyutai“ išleidžia „Hibiki“: 2,7B realiojo laiko kalbos kalbėjimo ir kalbos į tekstą vertimas su beveik žmogaus kokybės ir balso perdavimu
Realiojo laiko kalbos vertimas yra sudėtingas iššūkis, reikalaujantis sklandaus kalbos atpažinimo, mašininio…

„IBM AI“ išleidžia Granito ir viziją-33.1-2b: Mažo vizijos kalbos modelis su ypač įspūdingu atlikimu atliekant įvairias užduotis
Vaizdinių ir tekstinių duomenų integracija į dirbtinį intelektą kelia sudėtingą iššūkį. Tradiciniai…

Ar AI gali suprasti potekstę? Naujas AI požiūris į natūralios kalbos išvadą
Netiesioginės prasmės supratimas yra esminis žmogaus bendravimo aspektas. Vis dėlto dabartiniai natūralios…

Kiekybinio erdvės panaudojimo greitis (QSUR): naujas kvantizavimo metodas, skirtas padidinti didelių kalbos modelių efektyvumą (LLM) (LLM)
Po mokymo kvantizavimas (PTQ) Dėmesys yra skirtas sumažinti dydį ir pagerinti didelių…
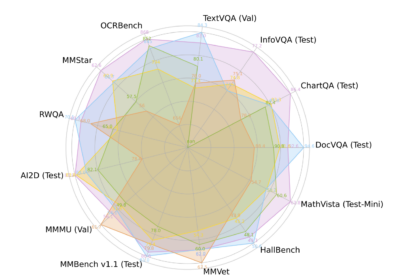
„NVIDIA AI“ išleidžia „Eagle2“ serijos vizijos kalbos modelį: SOTA rezultatų pasiekimas įvairiuose multimodaliniuose etalonuose
„Vision-Language“ modeliai (VLMS) žymiai išplėtė AI sugebėjimą apdoroti multimodalinę informaciją, tačiau jie…
