

Kornelio ir „Google“ tyrėjai pristato vieningą regresijos kalbos modelį (RLM), kuris prognozuoja skaitinius rezultatus tiesiogiai iš kodų eilučių-GPU branduolio latencijos, programos atminties naudojimo ir net neuroninio tinklo tikslumo ir latencijos, be rankomis sukurtų funkcijų. Iš T5-Gemma inicijuotas 300 m parametro kodavimo įrenginys-pasiekia stiprias rango koreliacijas nevienalyčiose užduotyse ir kalbose, naudodamas vieną teksto dekoderį, skleidžiantį skaitmenis su ribotu dekodavimu.
Kas tiksliai yra nauja?
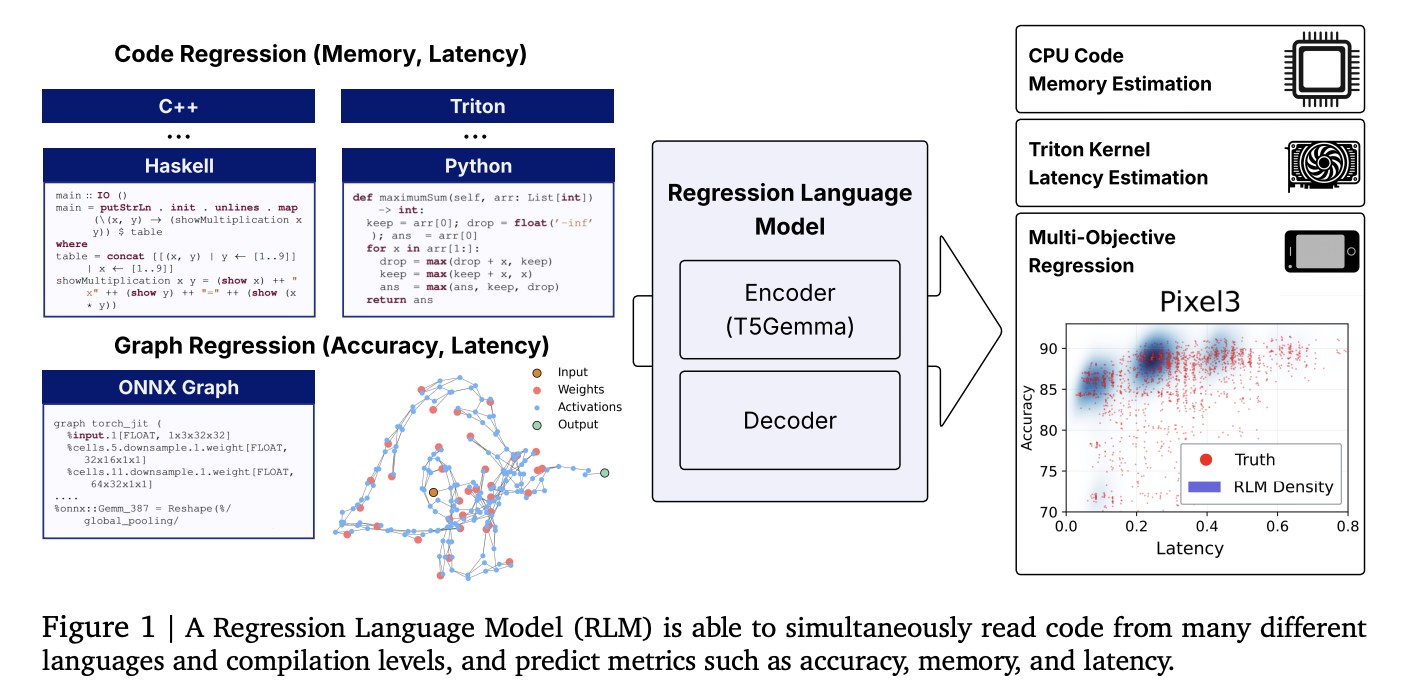
- Vieninga kodo ir metro regresija: Vienas RLM prognozuoja (i) didžiausią atmintį iš aukšto lygio kodo (Python/c/c ++ ir daugiau), (ii) „Triton GPU“ branduolių latentinis latentinis latentinis ir (iii) tikslumas ir aparatinei įrangai būdingas latentinis latentinis latentinis latentinis iš ONNX grafikų-skaityti neapdorotus teksto reprezentacijas ir atskirti skaičių. Nereikia jokių funkcijų inžinerijos, grafiko kodavimo įrenginių ar nulinių kainų tarpinių serverių.
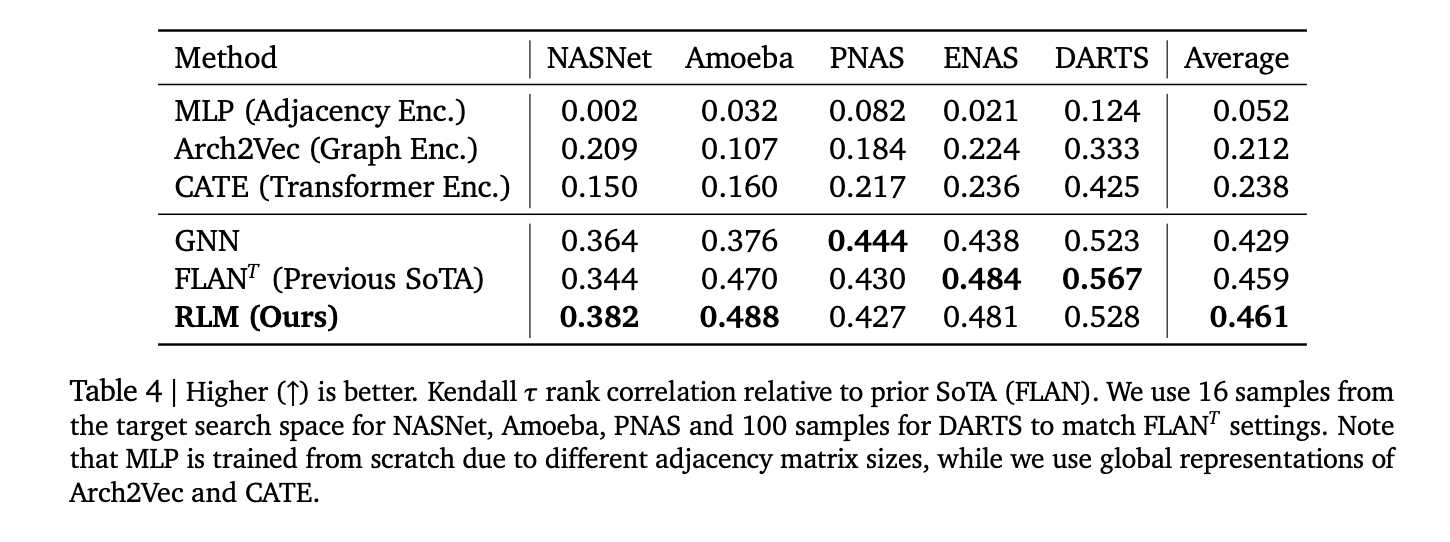
- Konkretūs rezultatai: Praneštos koreliacijos apima Spearman ρ ≈ 0,93 „Apps Leetcode“ atmintyje, ρ ≈ 0,52 „Triton“ branduolio latencijai, ρ> 0,5 vidurkis 17 „Codenet“ kalbosir Kendall τ ≈ 0,46 Penkiose klasikinėse NAS erdvėse-kompozicija su ir kai kuriais atvejais viršijant grafiko prognozuotojus.
- Daugiakalbis dekodavimas: Kadangi dekoderis yra autoregresyvus, modelio sąlygos vėlesnės metrikos (pvz., Tikslumas → Latencijos vienodai), fiksuojant realius kompromisus išilgai Pareto frontų.
Kodėl tai yra svarbu?
Našumo prognozavimo vamzdynai kompiliatoriuose, GPU branduolio pasirinkimas ir NAS paprastai priklauso nuo specialių funkcijų, sintaksės medžių ar GNN kodavimo įrenginių, trapių naujų OPS/kalbų. Regresijos traktavimas kaip Kitas numatytas numeris Standartizuoja krūvą: ženklina įvestis kaip paprastą tekstą (šaltinio kodas, „Triton IR“, „onnx“), tada iššifruokite kalibruotas skaičių stygas skaitmenų pagal suvaržytą mėginių ėmimą. Tai sumažina priežiūros sąnaudas ir pagerina perkėlimą į naujas užduotis, perteikdamas derinimą.
Duomenys ir etalonai
- „Code-Regression“ duomenų rinkinys (HF): Kuruojamas palaikymas Kodas-metrika Užduotys, apimančios programas/„Leetcode“, „Triton“ branduolio latencijos (iš branduolinių knygų išvestų) ir „Codenet“ atminties pėdsakų.
- NAS/ONNX Suite: „Nasbench-101/201“ architektūros, FBNET, kartą visiems (MB/PN/RN), „Twopath“, „Hiaml“, „Inception“ ir NDS yra eksportuojamos į ONNX tekstas numatyti tikslumą ir konkrečiam įrenginiui būdingam latencijai.
Kaip tai veikia?
- Stuburas: Kodavimo įrenginys – su a T5-Gemma Koderio inicijavimas (~ 300M parametrai). Įvestys yra neapdorotos eilutės (kodas arba onnx). Išėjimai yra numeriai, skleidžiami kaip Pasirašymo/eksponento/mantissa skaitmenų žetonai; Suvaržytas dekodavimas įgyvendina galiojančius skaitmenis ir palaiko netikrumą imant atranką.
- Abliacijos: (i) kalbos išankstinė vertė pagreitina konvergenciją ir pagerina „Triton“ latencijos prognozę; (ii) Tik dekoderio skaičių emisija pralenkia MSE regresijos galvutes net ir su y-normalizavimu; (iii) išmokti žetonų, specializuotų ONNX operatoriams, padidina veiksmingą kontekstą; (iv) ilgesni kontekstai; v) Didesnio „Gemma“ kodavimo įrenginio mastelio keitimas dar labiau pagerina koreliaciją su tinkamu derinimu.
- Mokymo kodas. regresas-lm Biblioteka teikia teksto ir teksto regresijos komunalines paslaugas, suvaržytą dekodavimą ir daugialypės užduotys išankstinius/tikslinimo receptus.
Svarbi statistika
- Programos (Python) atmintis: Spearmanas ρ> 0,9.
- „Codenet“ (17 kalbų) Atmintis: vidurkis ρ> 0,5; Stipriausios kalbos yra C/C ++ (~ 0,74–0,75).
- „Triton“ branduoliai (A6000) latentinis: ρ ≈ 0,52.
- NAS reitingas: vidurkis Kendall τ ≈ 0,46 visame nasnet, ameba, pNas, enas, smiginyje; Konkurencinga su FLAN ir GNN bazinėmis linijomis.
Pagrindiniai takeliai
- Vieningi kodo ir metrinės regresijos darbai. Vienas ~ 300 m parametras T5Gemma initializuotas modelis („RLM“) prognozuoja: (a) atminties iš aukšto lygio kodo, b) Triton GPU branduolio latencijos ir (c) modelio tikslumo + įrenginio latentinis latentinis iš ONNX-tiesiogiai iš teksto, be rankomis sukurtų funkcijų.
- Tyrimas rodo, kad „Spearman“ ρ> 0,9 Apps atmintyje, ≈0,52 dėl „Triton Latency“,> 0,5 vidutiniškai 17 „Codenet“ kalbų, o Kendall-≈ 0,46-penkiose NAS erdvėse.
- Skaičiai dekoduojami kaip tekstas su apribojimais. Vietoj regresijos galvutės RLM skleidžia skaitmeninius žetonus su suvaržytu dekodavimu, įgalindamas daugialypius, autoregresyvius išėjimus (pvz.
- Kodo regresas Duomenų rinkinys suvienija programas/„Leetcode“ atmintį, „Triton“ branduolio latentinį ir „Codenet“ atmintį; regresas-lm Biblioteka teikia mokymo/dekodavimo krūvą.
Labai įdomu, kaip šis darbas pertvarko našumo prognozę kaip „Tex-to-Number“ generavimą: kompaktiškas T5Gemma initializuotas RLM skaitymo šaltinis (Python/C ++), „Triton“ branduoliai arba ONNX grafikai ir skleidžia kalibruotą skaičių per suvaržytą dekodavimą. Pateiktos koreliacijos-APPS atmintis (ρ> 0,9), „Triton“ latentinis LTX A6000 (~ 0,52) ir NAS KENDALL-≈0,46-yra pakankamai stiprūs, kad būtų svarbu kompiliatoriai, branduolių genėjimui ir daugiabriauniai NAS triage be atskirų savybių ar GNN. Atviras duomenų rinkinys ir biblioteka daro replikaciją tiesmukiškai ir sumažina naujos aparatūros ar kalbų derinimo barjerą.
🚨 (Rekomenduojama skaityti) „Vipe“ (vaizdo įrašų pozos variklis): galingas ir universalus 3D vaizdo anotacijos įrankis erdvės AI
Peržiūrėkite Popierius„GitHub“ puslapis ir Duomenų rinkinio kortelė. Nesivaržykite patikrinti mūsų „GitHub“ puslapis, skirtas vadovėliams, kodams ir užrašų knygelėms. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 100K+ ml subreddit ir užsiprenumeruokite Mūsų informacinis biuletenis. Palauk! Ar jūs ant telegramos? Dabar galite prisijungti ir prie mūsų „Telegram“.
Asif Razzaq yra „MarkTechPost Media Inc“ generalinis direktorius. Kaip vizionierius verslininkas ir inžinierius, ASIF yra įsipareigojęs išnaudoti dirbtinio intelekto potencialą socialiniam gėrybei. Naujausias jo siekis yra dirbtinio intelekto žiniasklaidos platformos „MarkTechPost“, kuri išsiskiria išsamia mašininio mokymosi ir giluminio mokymosi naujienų, kuri yra techniškai pagrįsta, ir lengvai suprantama plačiai auditorijai. Platforma gali pasigirti daugiau nei 2 milijonai mėnesinių peržiūrų, parodydama jos populiarumą tarp auditorijos.
🙌 Sekite „MarkTechPost“: pridėkite mus kaip pageidaujamą šaltinį „Google“.





