

Objekto „Object“ (OVD) atvirojo balsavimo objekto nustatymo (OVD) siekiama aptikti savavališkus objektus su vartotojo pateiktomis teksto etiketėmis. Nors naujausia pažanga padidino „Zero-Shot“ aptikimo gebėjimą, dabartiniai metodai patiria kliūtį trimis svarbiais iššūkiais. Jie labai priklauso nuo brangių ir plataus masto regiono lygio anotacijų, kurias sunku išplėsti. Jų antraštės paprastai yra trumpos ir nėra turtingos kontekste, todėl jie yra nepakankami apibūdinant ryšius tarp objektų. Šiems modeliams taip pat trūksta stipraus naujų objektų kategorijų apibendrinimo, daugiausia siekiant suderinti atskiras objekto ypatybes su tekstinėmis etiketėmis, o ne naudoti holistinį scenos supratimą. Šių apribojimų įveikimas yra būtinas norint toliau stumti lauką ir sukurti efektyvesnius bei universalius regėjimo kalbos modelius.
Ankstesni metodai bandė sustiprinti OVD našumą, naudodamasi regėjimo kalba išankstiniu būdu. Tokie modeliai kaip „Glip“, „Glipv2“ ir „DetClipv3“ sujungia kontrastinį mokymosi ir tankius antraštės metodus, kad būtų skatinamas objekto teksto suderinimas. Tačiau šie metodai vis dar turi svarbių problemų. Regiono antraštės apibūdina tik vieną objektą, neatsižvelgiant į visą sceną, kuri apsiriboja kontekstiniu supratimu. Treniruotės apima milžiniškus etiketes duomenų rinkinius, taigi mastelio keitimas yra svarbus klausimas. Be būdo suprasti išsamią vaizdų lygio semantiką, šie modeliai nesugeba efektyviai aptikti naujų objektų.
Tyrėjai iš Sun Yat-sen universiteto, „Alibaba Group“, „Peng Cheng“ laboratorijos, Guangdongo provincijos pagrindinės informacijos saugumo technologijos laboratorijos ir Pazhou laboratorijos laboratorija siūlo LLMDET-naują atviro vokabularinį detektorių, apmokytą prižiūrint didelę kalbos modelį. Ši sistema pristato naują duomenų rinkinį „GroundingCAP-1M“, kurį sudaro 1,12 milijono vaizdų, kiekvienas anotuojamas su išsamiais vaizdų lygio antraštėmis ir trumpais regiono lygio aprašymais. Integracija tiek išsami, tiek glausta tekstinė informacija sustiprina vizijos kalbos derinimą, suteikdamas turtingesnę priežiūrą objektų aptikimui. Siekdama padidinti mokymosi efektyvumą, mokymo strategijoje naudojama dviguba priežiūra, derinant įžeminimo nuostolius, suderinančius teksto etiketes su aptiktais objektais ir antraščių generavimo nuostolius, palengvinančius išsamius vaizdo aprašymus kartu su objekto lygio antraštėmis. Įtrauktas didelis kalbos modelis, skirtas generuoti ilgas antraštes, apibūdinančias visas scenas ir trumpas frazes atskirų objektų, gerinant aptikimo tikslumą, apibendrinimą ir retos klasės atpažinimą. Be to, šis požiūris prisideda prie daugialypio mokymosi, sustiprindamas objektų aptikimo ir didelio masto regėjimo kalbos modelių sąveiką.
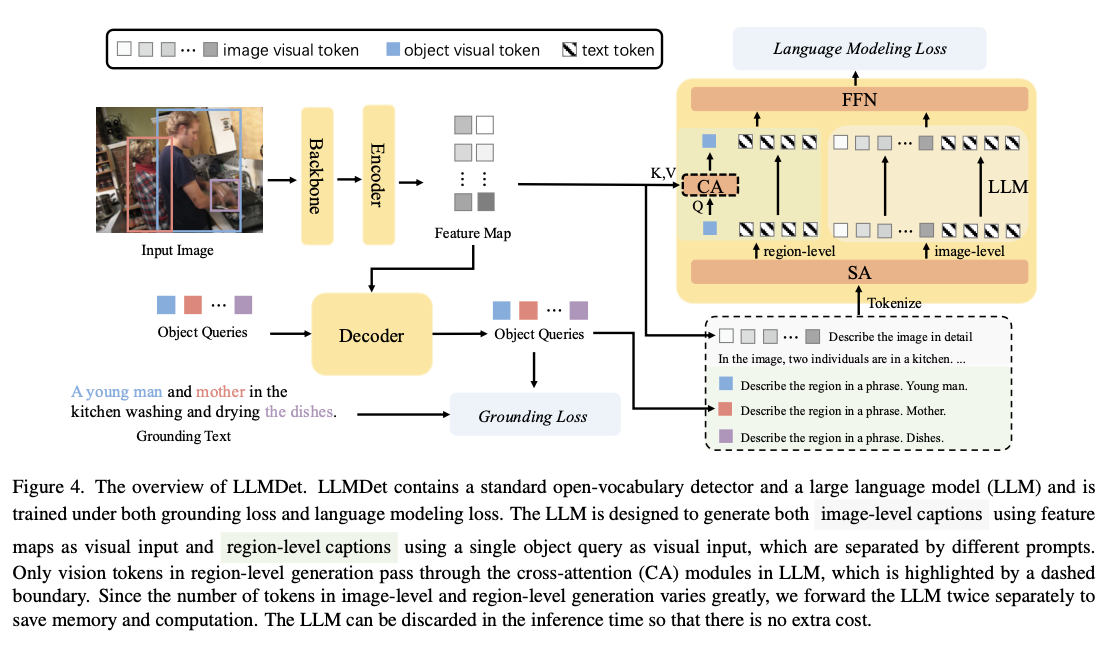
Treniruotės vamzdyną sudaro du pirminiai etapai. Pirma, projektorius yra optimizuotas, kad būtų galima suderinti objekto detektoriaus vaizdines ypatybes su didelės kalbos modelio funkcijų erdve. Kitame etape detektoriui sekasi suderinti su kalbos modeliu, naudodamas įžeminimo ir antraštės nuostolių derinį. Šiam mokymo procesui naudojamas duomenų rinkinys yra sudarytas iš „Coco“, „V3DET“, „GoldG“ ir LCS, užtikrinant, kad kiekvienas vaizdas būtų anotuotas tiek trumpais regiono lygio aprašymais, tiek su plačiomis ilgomis antraštėmis. Architektūra yra sukurta ant „Swin Transformer“ stuburo, naudojant „MM-Glinino“ kaip objekto detektorių, integruojant antraštės galimybes per dideles kalbos modelius. Modelis apdoroja informaciją dviem lygiais: regiono lygio aprašymai suskirsto objektus, o vaizdo lygio antraštės užfiksuoja visos scenos kontekstinius ryšius. Nepaisant to, kad mokymo metu įtrauktas pažengęs kalbos modelis, skaičiavimo efektyvumas išlaikomas, nes kalbos modelis yra atmetamas išvadų metu.
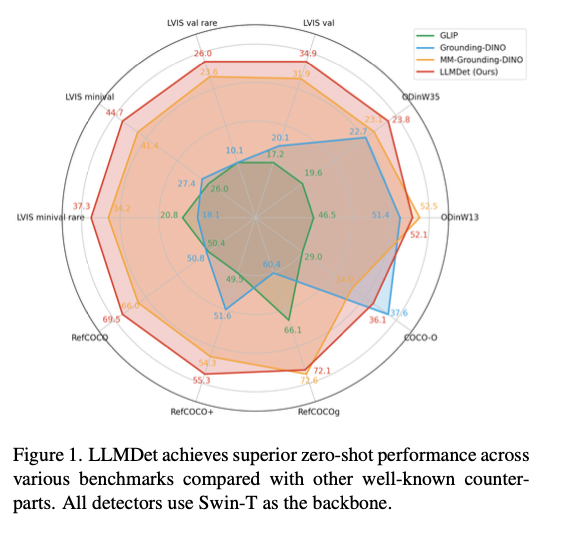
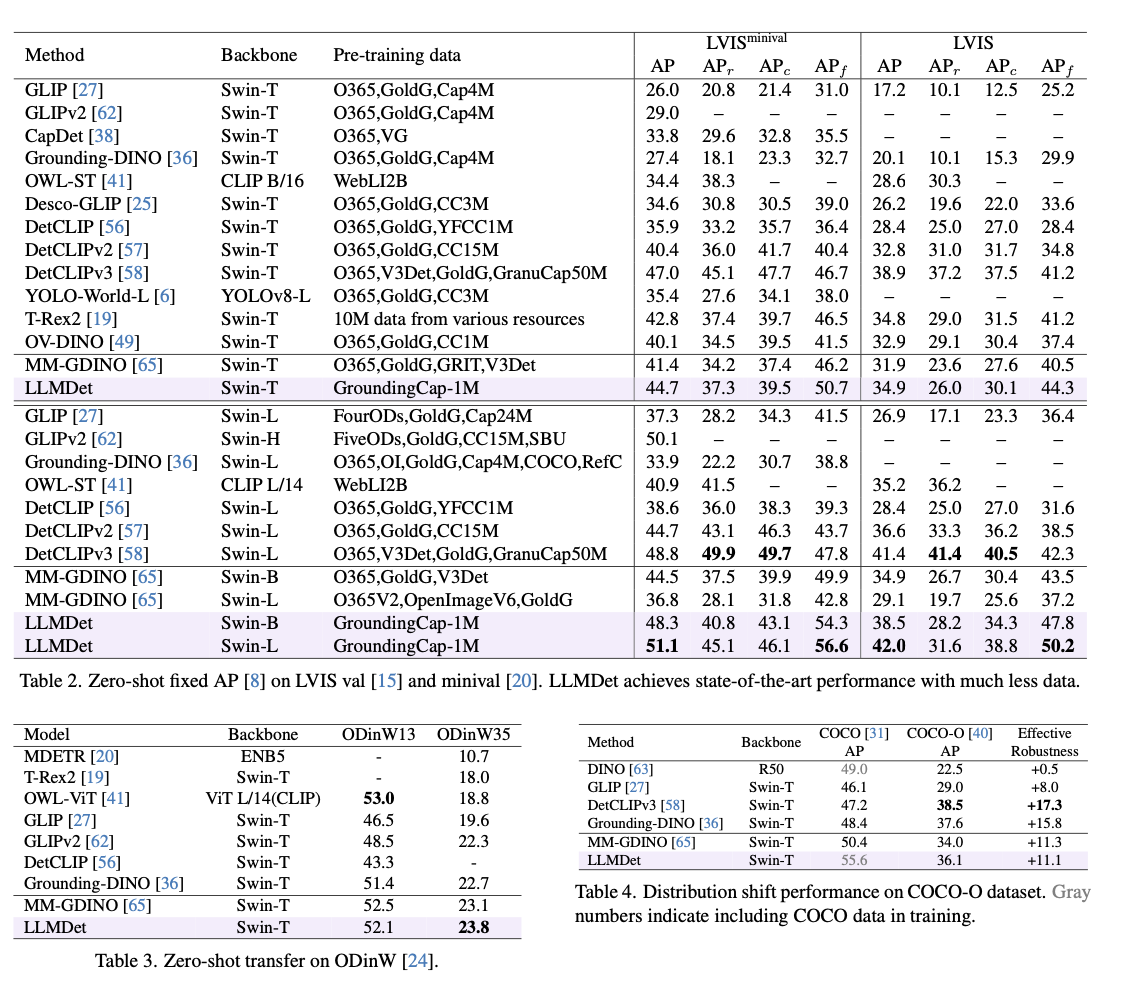
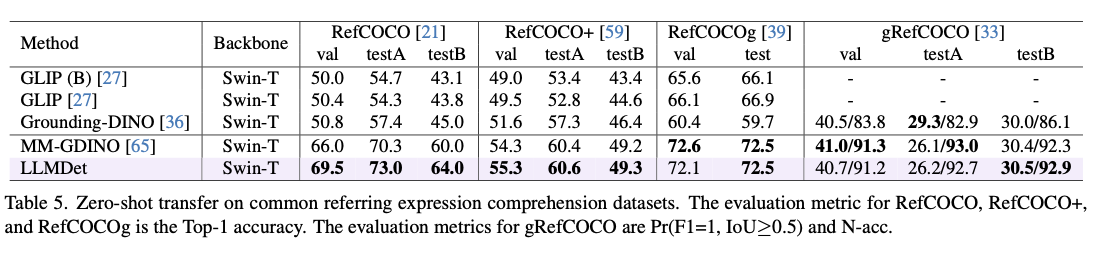
Šis metodas pasiekia moderniausius našumą įvairiuose atvirojo vokiškojo objektų aptikimo etalonuose, žymiai pagerinant aptikimo tikslumą, apibendrinimą ir tvirtumą. Ankstesniuose modeliuose jis pranoksta LVIS 3,3–14,3% AP, aiškiai pagerėjus retų klasių identifikavimui. „Odinw“, objekto aptikimo etalone per įvairius domenus, jis rodo geresnį nulinio kadro pernešimą. Tvirtumas domeno perėjimui taip pat patvirtinamas pagerinus „Coco-O“, duomenų rinkinio, matuojančio natūralius variantus, našumą. Atliekant referencinės išraiškos supratimo užduotis, jis pasiekia geriausią „Refcoco“, „Refcoco+“ ir „Refcocog“ tikslumą, patvirtindamas jo galimybes teksto aprašymui suderinti su objekto aptikimu. Abliacijos eksperimentai rodo, kad vaizdų lygio antraštės ir regionų lygio įžeminimas kartu labai prisideda prie našumo, ypač tiriant retus objektus. Be to, išmokto detektoriaus įtraukimas į daugiamodalinius modelius pagerina regėjimo kalbos derinimą, slopina haliucinacijas ir padidina vizualinio klausimų atsakymo tikslumą.
Naudodamas didelius kalbų modelius, aptikdami atvirą balsą, „LLMDET“ pateikia keičiamą ir efektyvią mokymosi paradigmą. Šis vystymasis ištaiso pagrindinius esamų OVD sistemų iššūkius, nes moderniausi veikimai keliuose aptikimo etalonuose ir pagerino nulinio šūvio apibendrinimą bei retos klasės aptikimą. Mokymosi vizijos kalba integracija skatina įvairių domenų pritaikomumą ir padidina daugialypę sąveiką, parodydama, kad pažada, kad bus vadovaujamasi kalbomis, atliekant objektų aptikimo tyrimus.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (Paaukštintas)
Aswinas AK yra „MarktechPost“ konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute Kharagpur. Jis aistringai vertina duomenų mokslą ir mašininį mokymąsi, sukelia stiprią akademinę patirtį ir praktinę patirtį sprendžiant realaus gyvenimo įvairių sričių iššūkius.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo





