

Po mokymo kvantizavimas (PTQ) Dėmesys yra skirtas sumažinti dydį ir pagerinti didelių kalbos modelių (LLM) greitį, kad jie būtų praktiškesni realiojo pasaulio naudojimui. Tokiems modeliams reikalingi dideli duomenų kiekiai, tačiau stipriai iškreiptas ir labai nevienalytis duomenų pasiskirstymas kvantizavimo metu sukelia didelių sunkumų. Tai neišvengiamai padidintų kvantizavimo diapazoną, todėl, daugumos verčių, jis būtų mažiau tiksli išraiška ir sumažins bendrąjį modelio tikslumą. Nors PTQ metodai siekia išspręsti šias problemas, iššūkiai vis dar yra veiksmingai paskirstant duomenis visoje kvanalizacijos erdvėje, ribodami optimizavimo potencialą ir trukdant platesniam diegimui išteklių ribotoje aplinkoje.
Dabartiniai didelių kalbų modelių (LLMS) kiekybinio kvantizavimo (PTQ) metodai daugiausia dėmesio skiria tik svoriui ir svorio aktyvavimo kvantizavimui. Tik svorio metodai, tokie kaip GPTQAr Awqir OWQbandykite sumažinti atminties naudojimą, sumažindami kvantizavimo klaidas arba pašalindami aktyvacijos nuokrypius, tačiau nesugeba optimizuoti visų verčių tikslumo. Technikos, kaip Quip ir QUIP# Naudokite atsitiktines matricas ir vektorių kiekybinį nustatymą, tačiau tvarkant ekstremalius duomenų pasiskirstymus, išlikite ribotos. Svorio aktyvavimo kvantizavimas siekia pagreitinti išvadą kiekybiškai ir aktyvuoti. Vis dėlto, tokie metodai SklandžiusAr NULEQUANTir Karjeras kova valdyti aktyvavimo nuokrypių dominavimą, sukeldamas daugelio vertybių klaidas. Apskritai, šie metodai priklauso nuo euristinių metodų ir nesugeba optimizuoti duomenų pasiskirstymo visoje kvantizavimo erdvėje, o tai riboja našumą ir efektyvumą.
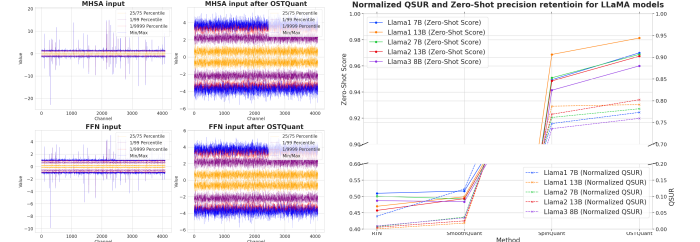
Siekdami išspręsti euristinio kvantizavimo (PTQ) metodų (PTQ) metodų apribojimus ir metrikos trūkumą kiekybiniam efektyvumui įvertinti, tyrėjai iš HouoMo AI, Nanjingo universitetas, ir Pietryčių universitetas pasiūlė Kiekybinis erdvės panaudojimo greičio (QSUR) koncepcija. „QSUR“ matuoja, kaip veiksmingai svorio ir aktyvavimo pasiskirstymas naudoja kvantizavimo erdvę, siūlant kiekybinį pagrindą įvertinti ir patobulinti PTQ metodus. Metrinės svertinės statistinės savybės, tokios kaip savitvarės skilimas ir pasitikėjimo elipsoidai, kad apskaičiuotų svorio ir aktyvacijos pasiskirstymo hipervatyvumą. QSUR analizė parodo, kaip linijinės ir sukimosi transformacijos daro įtaką kvantizavimo efektyvumui, o specifiniai metodai sumažina tarp kanalų skirtumus ir sumažina pašalinius dalykus, kad padidintų našumą.
Tyrėjai pasiūlė Ostquant Framework, sujungianti stačiakampius ir mastelio keitimo transformacijas, siekiant optimizuoti didelių kalbos modelių svorio ir aktyvavimo pasiskirstymą. Šis požiūris integruoja mokomasi lygiaverčių įstrižainės mastelio ir stačiakampių matricų transformacijos poras, užtikrinančias skaičiavimo efektyvumą, tuo pačiu išsaugant ekvivalentiškumą kiekybiškai. Tai sumažina perpildymą, nepakenkiant originalaus tinklo išvestims išvadų metu. Ostquant naudoja mokymąsi tarp bloko, kad būtų galima skleisti transformacijas visame pasaulyje Llm blokai, naudojamos technikos Svorio mažinimo minimizavimo inicijavimas (WOMI) Veiksmingam inicijavimui. Metodas pasiekia aukštesnį QSURsumažina paleidimo laiką ir padidina kiekybinį našumą LLM.
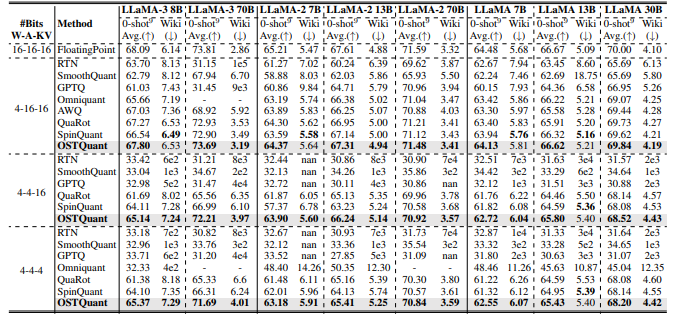
Vertinimo tikslais tyrėjai kreipėsi Ostquant į Lama šeima (Llama-1, llama-2, ir Lama-3) ir įvertino našumą naudojant pasipiktinimą „Wikitext2“ ir devynios „Zero-Shot“ užduotys. Palyginti su tokiais metodais SklandžiusAr GPTQAr Karjerasir SpinquantasAr Ostquant nuosekliai juos aplenkė, bent jau pasiekdamas 99,5% plūduriuojančio taško tikslumas po 4-16-16 sąranka Ir žymiai susiaurino našumo spragas. Lama-3-8b atsirado tik a 0,29-Point lašas Nulio šūvių užduotyspalyginti su viršijančiais nuostoliais 1,55 taškai kitiems. Sunkesniais scenarijais Ostquantas buvo geresnis už „Spinquant“ ir įgijo tiek, kiek 6.53 taškai iki Llama-2 7b 4-4-16 sąrankoje. „KL-Top“ praradimo funkcija užtikrino geriau semantiką ir sumažintą triukšmą, taip padidindama našumą ir mažinant tarpus W4A4KV4 iki 32%. Šie rezultatai tai parodė Ostquant yra veiksmingiau tvarkant ir užtikrinant, kad paskirstymai būtų labiau nešališki.

Galų gale siūlomas metodas optimizavo duomenų pasiskirstymą kiekybinės erdvėje, remiantis QSUR metrika ir nuostolių funkcija, KL-TOP, gerinant didelių kalbų modelių našumą. Esant mažai kalibravimo duomenims, jis sumažino triukšmą ir išsaugojo semantinį turtingumą, palyginti su esamais kiekybinio nustatymo metodais, pasiekdamas aukštą našumą keliuose etalonuose. Ši sistema gali būti pagrindas būsimam darbui, pradedant procesą, kuris padės tobulinti kvantizavimo metodus ir padaryti modelius efektyvesnius programas, reikalaujančias didelio skaičiavimo efektyvumo išteklių apribotuose aplinkose.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 70K+ ml subreddit.
🚨 (Rekomenduojama skaityti) „Nebius AI Studio“ plečiasi su „Vision“ modeliais, naujais kalbų modeliais, įterpimais ir „Lora“ (Paaukštintas)
„Divyesh“ yra konsultavimo praktikantas „MarktechPost“. Jis siekia žemės ūkio ir maisto inžinerijos BTech iš Indijos technologijos instituto Kharagpur. Jis yra duomenų mokslo ir mašinų mokymosi entuziastas, norintis integruoti šias pagrindines technologijas į žemės ūkio sritį ir išspręsti iššūkius.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo






