

Netiesioginės prasmės supratimas yra esminis žmogaus bendravimo aspektas. Vis dėlto dabartiniai natūralios kalbos išvados (NLI) modeliai stengiasi pripažinti numanomus įsiurbimus – logiškai išvados, bet ne aiškiai nurodytos, logiškai. Daugelis dabartinių NLI duomenų rinkinių yra orientuoti į aiškius įsipareigojimus, todėl modeliai yra nepakankami, kad būtų galima spręsti scenarijus, kuriuose reikšmė yra netiesiogiai išreikšta. Šis apribojimas skatina tokių programų kaip pokalbio AI, apibendrinimo ir konteksto jautrų sprendimų priėmimo plėtrą, kai gebėjimas daryti išvadą apie neišsakytus padarinius yra labai svarbus. Norint sušvelninti šį trūkumą, reikalingas duomenų rinkinys ir požiūris, kuris sistemingai įtraukia numanomus NLI užduočių pateikimus.
Dabartiniuose NLI etalonuose, tokiuose kaip SNLI, MNLI, Anli ir WanLI, daugiausia dominuoja aiškūs įsipareigojimai, o numanomi sudedamieji elementai sudaro nereikšmingą duomenų rinkinio dalį. Todėl moderniausi modeliai, apmokyti šiose duomenų rinkiniuose, paprastai klaidingai numanė, kad priskyrimai yra neutralūs ar prieštaringi. Ankstesnės pastangos įdiegti supratimą apie implikaciją buvo sutelktos į struktūrizuotus įvestis, tokias kaip netiesioginis klausimų ir atsakymų ar iš anksto apibrėžtų loginių santykių, kurie nėra apibendrinti laisvos formos samprotavimų nustatymais. Net dideli modeliai, tokie kaip „GPT-4“, parodo didelį našumo atotrūkį tarp aiškaus ir numanomo aptikimo, dėl kurio reikia išsamesnio požiūrio.
„Google Deepmind“ ir Pensilvanijos universiteto tyrėjai pasiūlė numanomą NLI (INLI) duomenų rinkinį, kad užpildytų atotrūkį tarp aiškių ir netiesioginių įsakymų natūralių kalbų išvadų (NLI) modeliuose. Jų dokumente siūlomas sistemingas metodas, kaip įtraukti numanomą prasmę NLI mokymuose, naudojant struktūrizuotus implikacines sistemas iš dabartinių duomenų rinkinių, tokių kaip „Ludwig“, „Circa“, „Normbank“ ir „Socialchem“, kad šias sistemas paverstų šias sistemas, susijusias su numanomu įsipareigojimu. Be to, kiekviena prielaida taip pat yra suporuota su aiškiais įsipareigojimais, neutraliomis hipotezėmis ir prieštaravimais, kad būtų sukurtas įtraukiantis duomenų rinkinys modelio mokymui. Novatoriškas kelių kadrų raginimo metodas naudojant „Gemini-Pro“ užtikrina aukštos kokybės numanomo padalijimo generavimą, tuo pačiu kartu sumažinant anotacijos išlaidas ir užtikrinant duomenų vientisumą. Netiesioginės reikšmės įtraukimas į NLI užduotis leidžia diferencijuoti aiškų ir numanomus modelius, turinčius didesnį tikslumą.
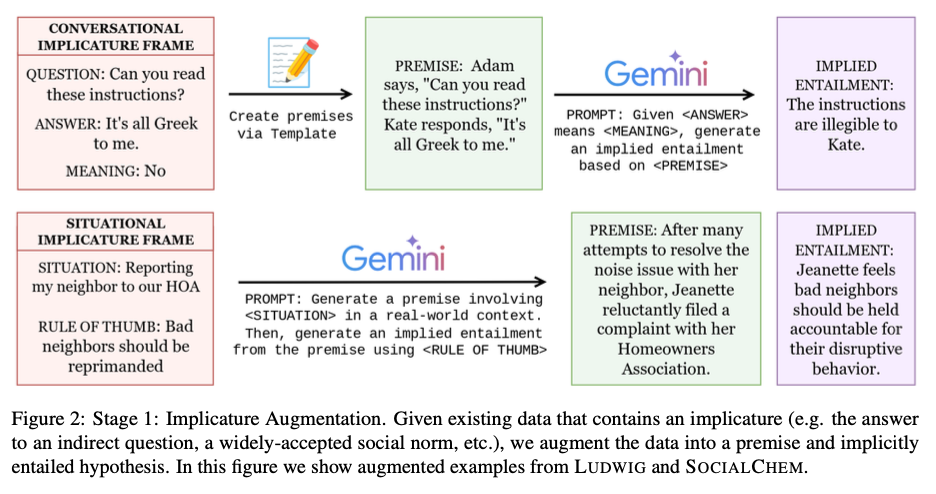

„InLI“ duomenų rinkinio sukūrimas yra dviejų pakopų procedūra. Pirmiausia esami struktūrizuotos duomenų rinkiniai, turintys tokių implikacijų, kaip netiesioginiai atsakymai ir socialinės normos, yra pertvarkytos į neįžangintą įsipareigojimą, patalpos formatą. Antrajame etape siekiant užtikrinti duomenų rinkinio stiprumą, aiškūs sudedamieji reikalavimai, neutralūs teiginiai ir prieštaravimai sukuriami kontroliuojant manipuliuojant numanomais įsipareigojimais. Duomenų rinkinį sudaro 40 000 hipotezių (numanomų, aiškių, neutralių ir prieštaringų) 10 000 patalpų, siūlančių įvairius ir subalansuotus treniruočių rinkinį. Patobulinant eksperimentus, naudojant T5-XXL modelius, naudojami mokymosi normų diapazonas (1E-6, 5E-6, 1E-5) daugiau nei 50 000 mokymo veiksmų, siekiant pagerinti numanomų įsipareigojimų identifikavimą.
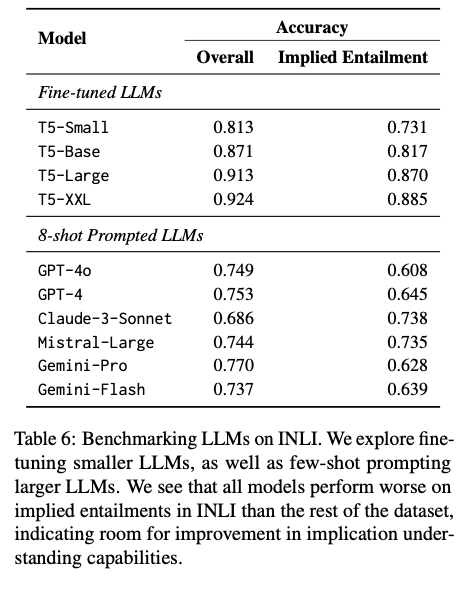
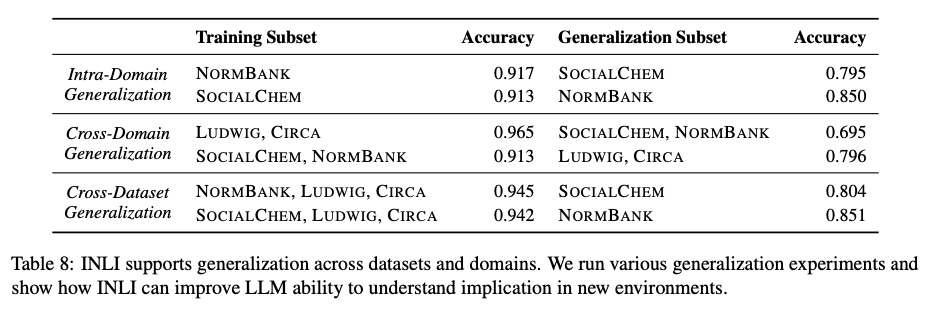
Modeliai, suderinti su INLI, rodo dramatišką numanomo įsipareigojimų aptikimo pagerėjimą, o optimalus tikslumas yra 92,5%, palyginti su 50–71% tikslumu modeliams, pritaikytiems tipiniams NLI duomenų rinkiniams. Patobulinti modeliai gerai apibendrina nematytus duomenų rinkinius, kurių tikslumas yra didelis, ir įvertina 94,5% „Normbank“ ir 80,4% „SocialChem“, nustatant INLS patikimumą įvairiose srityse. Be to, tik hipotezės bazinės linijos įrodo, kad modeliuojami modeliai, suderinami su „InLI“ svertu ir prielaida, ir hipotezė, kad būtų galima daryti išvadą, mažinant sekliojo modelio mokymosi tikimybę. Šie rezultatai nustato „InLi“ patikimumą, kai įveikia aiškius ir netiesioginius padarinius, o savo ruožtu iš esmės pagerinant AI gebėjimą rafinuotam žmonių bendravimui.
Straipsnyje reikšmingai prisideda NLI, siūlant numanomą NLI (INLI) duomenų rinkinį, kuris sistemingai įveda numanomą prasmę į išvadų užduotis. Naudojant struktūrizuotus implikacijos rėmus ir alternatyvią hipotezės generavimą, šis požiūris pagerina modelio tikslumą nustatant netiesioginius įsipareigojimus ir palengvina geresnį apibendrinimą tarp sričių. Turėdamas tvirtų empirinių įrodymų, patvirtinančių jo tvirtumą, „InLi“ sukuria naują etaloną mokant AI modelius, kad būtų galima nustatyti netiesioginę prasmę, ir tai lemia niuansuotą ir kontekstą suvokiantį natūralios kalbos supratimą.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 70K+ ml subreddit.
🚨 Susipažinkite su „Intellagent“: atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą (Paaukštintas)
Aswinas AK yra „MarktechPost“ konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute Kharagpur. Jis aistringai vertina duomenų mokslą ir mašininį mokymąsi, sukelia stiprią akademinę patirtį ir praktinę patirtį sprendžiant realaus gyvenimo įvairių sričių iššūkius.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo






