Regresijos užduotys, apimančios nuolatinių skaitinių verčių prognozavimą, tradiciškai rėmėsi skaitmeninėmis galvutėmis, tokiomis kaip Gauso parametrai arba taškinės tensorinės projekcijos. Šie tradiciniai požiūriai turi tvirtus paskirstymo prielaidų reikalavimus, reikalauja daug etiketės duomenų ir linkę suskaidyti modeliuodami pažangius skaitmeninius pasiskirstymus. Nauji didelių kalbų modelių tyrimai pateikia kitokį požiūrį-pateikia skaitmenines vertes kaip diskrečiųjų žetonų sekas ir numatant automatinį dekodavimą. Tačiau šis poslinkis kyla su keliais rimtais iššūkiais, įskaitant poreikį efektyvaus žetonų mechanizmo, skaitinio tikslumo praradimo galimybių, poreikio išlaikyti stabilų mokymą ir poreikį įveikti indukcinių nuosekliųjų ženklų formų šališkumą skaitmeniniams ženklams. vertės. Atlikus šiuos iššūkius, būtų dar galingesnė, efektyvesnė duomenimis ir lanksčioji regresijos sistema, taip išplėsdama giluminio mokymosi modelių taikymą už tradicinių metodų ribų.
Tradiciniai regresijos modeliai priklauso nuo skaitmeninių tenzorių projekcijų ar parametrinių pasiskirstymo galvučių, tokių kaip Gauso modeliai. Nors šie įprasti metodai yra plačiai paplitę, jie taip pat turi keletą trūkumų. Gauso pagrindu sukurti modeliai turi trūkumų, kad paprastai paprastai paskirstytos išėjimai, ribojantys gebėjimą modeliuoti sudėtingesnius, multimodalinius paskirstymus. „Tiplewise“ regresijos vadovai kovoja su labai netiesiniais ar nepertraukiamais ryšiais, o tai riboja jų sugebėjimą apibendrinti įvairius duomenų rinkinius. Aukšto matmens modeliai, tokie kaip histogramos pagrįsti Riemann pasiskirstymas, yra skaičiavimo ir daug duomenų reikalaujantys, todėl neveiksmingi. Be to, daugeliui tradicinių požiūrių reikia aiškiai normalizuoti ar didinti išvestį, įvedant papildomą sudėtingumo ir galimo nestabilumo sluoksnį. Nors įprastas darbas bandė naudoti regresiją teksto ir teksto regresija, naudojant didelius kalbų modelius, buvo atliktas mažai sistemingo darbo „nieko iki teksto“ regresijos, kai skaitiniai išėjimai vaizduojami kaip žetonų sekos, tokiu būdu įvedant naują paradigmą skirta paradigma skirta paradigma, skirta Skaitmeninė prognozė.
„Google DeepMind“ tyrėjai siūlo alternatyvią regresijos formulę, pertvarkydami skaitinių numatymą kaip automatinės sekos generavimo problemą. Užuot tiesiogiai generuoję skaliarines reikšmes, šis metodas koduoja skaičius kaip žetonų sekas ir naudoja suvaržytą dekodavimą, kad būtų galima generuoti galiojančius skaitmeninius išėjimus. Koduojant skaitmenines reikšmes kaip atskiras žetonų sekas, šis metodas tampa lankstesnis ir išraiškingesnis modeliuojant realiai įvertintus duomenis. Skirtingai nuo Gauso pagrįstų metodų, šis metodas nereiškia stiprių paskirstymo prielaidų apie duomenis, todėl jis tampa labiau apibendrinamas realaus pasaulio užduotims su nevienalyčiais modeliais. Modelis pritaiko tikslų multimodalinio, sudėtingo pasiskirstymo modeliavimą, taip pagerindamas jo našumą atliekant tankio įvertinimą, taip pat į tašką regresijos užduotis. Pasinaudojant autoregresyvių dekoderių pranašumais, pasinaudojant naujausia kalbos modeliavimo pažanga, kartu išlaikant konkurencinį našumą, palyginti su standartinėmis skaitinėmis galvutėmis. Ši formuluotė pateikia tvirtą ir lanksčią sistemą, kuri tiksliai gali modeliuoti platų skaitinių ryšių diapazoną, siūlant praktinį standartinių regresijos metodų pakaitalą, kuris paprastai laikomas nelanksčiu.
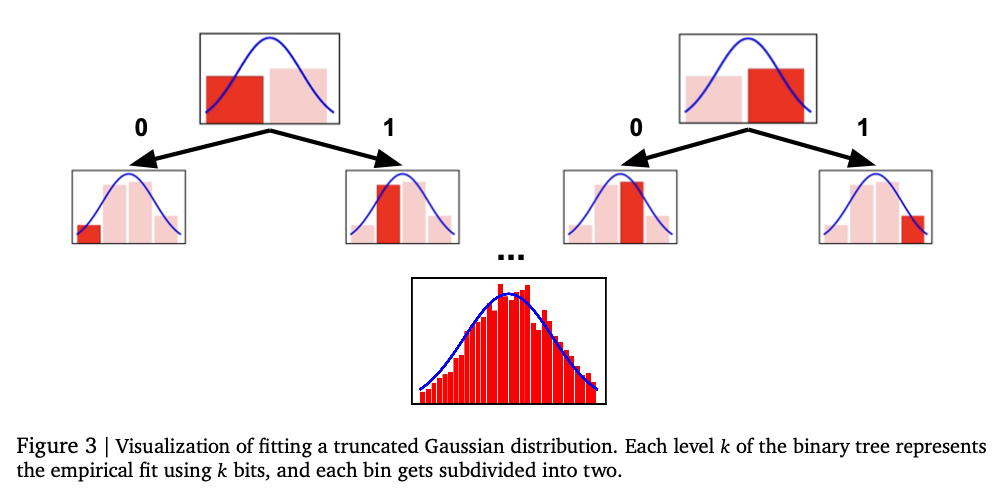
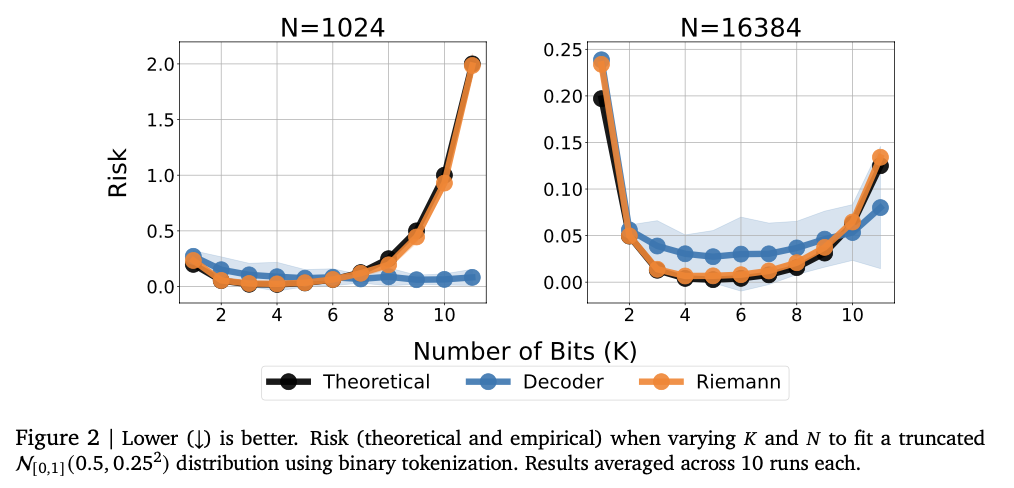
Šis metodas naudoja du skaitmeninių atvaizdų žetonų metodus: normalizuota tokenizacija ir nenormalizuota tokenizacija. Normalizuotas žetonas koduoja skaičius fiksuotame diapazone su „Base-B“ išplėtimu, kad būtų užtikrintas tikslumas didėjančiu sekos ilgiu. Nenormalizuotas žetonas praplečia tą pačią idėją iki platesnių skaitinių diapazonų su apibendrintu plūduriuojančio taško vaizdavimu, tokiu kaip IEEE-754, be būtinybės aiškiai normalizuoti. Transformatoriaus automatinis modelis generuoja skaitmeninius išėjimus žetonais pagal žetoną, atsižvelgiant į apribojimus, kad būtų galima pateikti galiojančias skaitmenines sekas. Modelis mokomas naudojant kryžminės entropijos praradimą per žetonų seką, kad būtų galima tiksliai atvaizduoti skaitinį. Užuot tiesiogiai numatę skaliarinį išvestį, sistemos pavyzdžiai yra žetonų sekos ir naudoja statistinio įvertinimo metodus, tokius kaip vidurkis ar vidutinis skaičiavimas, kad galutinai numatytume. Vertinimai atliekami naudojant „OpenML-Ctr23“ ir AMLB etalonų realaus pasaulio lentelių regresijos duomenų rinkinius ir palyginti su Gauso mišinio modeliais, histogramomis pagrįsta regresija ir standartinėmis taškinės regresijos galvutėmis. Hiperparametro derinimas atliekamas įvairiuose dekoderio nustatymuose, tokiuose kaip sluoksnių skaičiaus, paslėptų blokų ir žetonų žodynų skirtumai, kad būtų užtikrintas optimizuotas našumas.
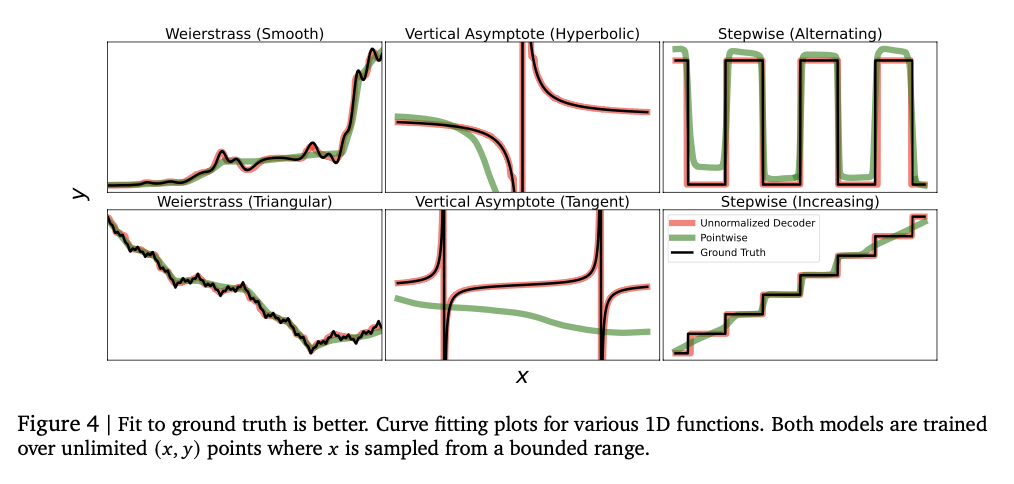
Eksperimentai rodo, kad modelis sėkmingai užfiksuoja sudėtingus skaitinius ryšius, pasiekdamas stiprius įvairias regresijos užduotis. Jis pasiekia aukštus Kendall-tau koreliacijos balus lentelių regresijoje, dažnai pralenkdami pradinius modelius, ypač esant žemų duomenų nustatymams, kur būtinas skaitinis stabilumas. Šis metodas taip pat geriau įvertinamas tankis, sėkmingai fiksuojant sudėtingus pasiskirstymus ir pralenkdami Gauso mišinio modelius ir Riemann pagrįstus metodus neigiamuose log-tikimybės bandymuose. Modelio dydžio derinimas pradžioje pagerina našumą, o per didelis pajėgumas sukelia perteklių. Skaitmeninis stabilumas labai pagerina klaidų taisymo metodus, tokius kaip žetonų kartojimas ir balsavimas daugumai, mažinant pažeidžiamumą už nuokrypius. Šie rezultatai daro šią regresijos sistemą tvirta ir adaptyvia tradicinių metodų alternatyva, parodanti jos gebėjimą sėkmingai apibendrinti įvairius duomenų rinkinius ir modeliavimo užduotis.
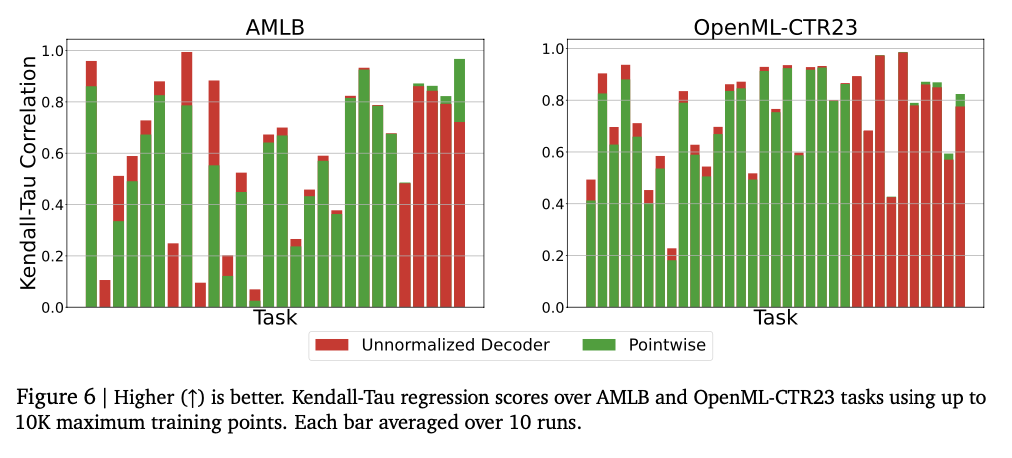
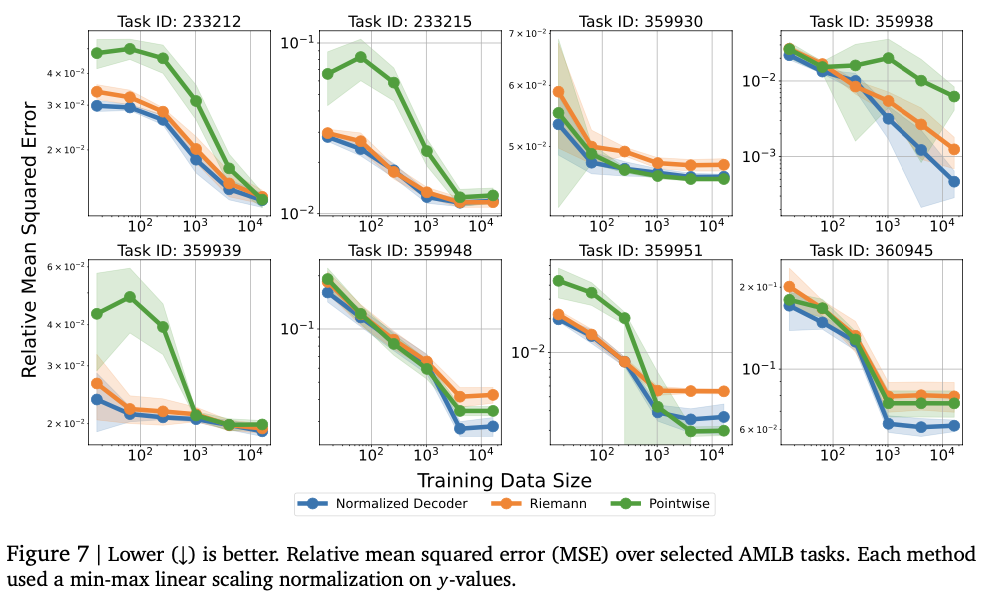
Šis darbas pristato naują požiūrį į skaičių numatymą, pasitelkiant žetonų vaizdus ir automatinį dekodavimą. Pakeisdama tradicines skaitinės regresijos galvutes su prieigos raktų išvestimis, sistema pagerina lankstumą modeliuojant realiai įvertintus duomenis. Tai pasiekia konkurencinius rezultatus atliekant įvairias regresijos užduotis, ypač įvertinant tankį ir modeliuojant lenteles, kartu suteikdamas teorines garantijas, susijusias su savavališkų tikimybių pasiskirstymais. Tai pralenkia tradicinius regresijos metodus svarbiuose kontekstuose, ypač modeliuojant sudėtingus pasiskirstymus ir nedaug mokymo duomenis. Ateitis darbas apima geresnio skaitinio tikslumo ir stabilumo neigiamos neigiamųjų metodų gerinimą, pagrindą išplėsti iki daugiapakopės regresijos ir didelio matmenų prognozavimo užduočių ir ištirti jos pritaikymą stiprinimo mokymosi apdovanojimų modeliavime ir regėjimo skaičiaus įvertinimui. Dėl šių rezultatų sekos pagrįsta skaitinė regresija yra perspektyvi tradicinių metodų alternatyva, išplėsdama užduočių, kurias kalbų modeliai gali sėkmingai išspręsti, apimtį.
Patikrinkite Popieriaus ir „GitHub“ puslapis. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 „MarkTechPost“ kviečia AI įmones/pradedančiuosius/grupes, kad jie galėtų partnerį už savo būsimus AI žurnalus „Atvirojo kodo AI gamyboje“ ir „Agentic AI“.
Aswinas AK yra „MarktechPost“ konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute Kharagpur. Jis aistringai vertina duomenų mokslą ir mašininį mokymąsi, sukelia stiprią akademinę patirtį ir praktinę patirtį sprendžiant realaus gyvenimo įvairių sričių iššūkius.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo