

Didelio kalbos modelis (LLM) – pagrįsta PG kompanionai iš paprastų pokalbių programų išsivystė į subjektus, kuriuos vartotojai suvokia kaip draugus, partnerius ar net šeimos narius. Nepaisant jų į žmogiškąjį gebėjimą, AI kompanionai dažnai kelia šališkumą, diskriminacinius ir kenksmingus teiginius. Šie šališkumai gali įgyvendinti būdingus stereotipus ir sukelti psichologines kančias, ypač atskirtose bendruomenėse. Įprasti vertės suderinimo metodai, kuriuos daugiausia kontroliuoja kūrėjai, negali numatyti ir patenkinti vartotojų poreikius pagal įprastus scenarijus. Vartotojams dažnai kyla diskriminacinė AI produkcija nesutikdami su jų vertybėmis, sukeldami nusivylimo ir bejėgiškumo jausmus. Priešingai, šiame dokumente tiriama nauja paradigma, kai patys vartotojai imasi iniciatyvos ištaisyti AI šališkumą keliais mechanizmais. Norint sukurti AI sistemas, įgalinančias bendruomenes, kurios suteikia bendruomenes, kad bendruomenės kartu su etiška įsitraukimu, būtina suprasti, kaip vartotojai naršo ir sumažina šiuos šališkumus.
Įprastinės AI šališkumo mažinimo strategijos, tokios kaip tikslinimas, greitas inžinerijos ir stiprinimo mokymasis naudojant žmonių atsiliepimus, yra pagrįstos kūrėjų intervencija iš viršaus į apačią. Nors šie mechanizmai bando pertvarkyti AI veiksmus su iš anksto nustatytomis etinėmis normomis, jie dažniausiai nesugeba valdyti įvairių ir dinamiškų būdų, kuriais vartotojai bendrauja su AI kompanionais. Dabartiniai bandymai atlikti algoritmo auditą pirmiausia siekia atrasti AI šališkumą ir negali išanalizuoti, kaip patys vartotojai sąmoningai stengiasi juos ištaisyti. Šie trūkumai liudija būtinybę turėti elastingesnį ir dalyvavimo mechanizmą, kai patys vartotojai geriau kontroliuoja AI elgesį.
Stanfordo universiteto, Carnegie Mellon universiteto, Honkongo miesto universiteto ir Tsinghua universiteto tyrėjai pristato vartotojo pagrįstą sistemą, kurioje individai aktyviai vaidina nustatant ir ištaisydami AI šališkumą. Šiame tyrime nagrinėjama, kaip vartotojai atlieka šią veiklą, analizuodami 77 socialinės žiniasklaidos ataskaitas apie diskriminacinius AI atsakymus ir pusiau struktūruotus interviu su 20 patyrusių AI kompanionų vartotojais. Priešingai nei įprastas kūrėjų vadovaujamas suderinimas, šis metodas yra susijęs su vartotojų agentūra formuojant AI elgesį. Tyrime atskleidžiami šešių tipų šališki AI atsakymai, trys konceptualūs modeliai, pagal kuriuos vartotojai atsižvelgia į AI elgesį, ir septyni skirtingi metodai, kuriuos vartotojai naudoja neutralizuoti šališkumą. Tyrimas prisideda prie bendro pokalbio apie žmogaus-Ai sąveiką, parodant, kad ne tik vartotojai nustato šališkumą, bet ir pertvarkyti AI reakcijas į jų vertybes.
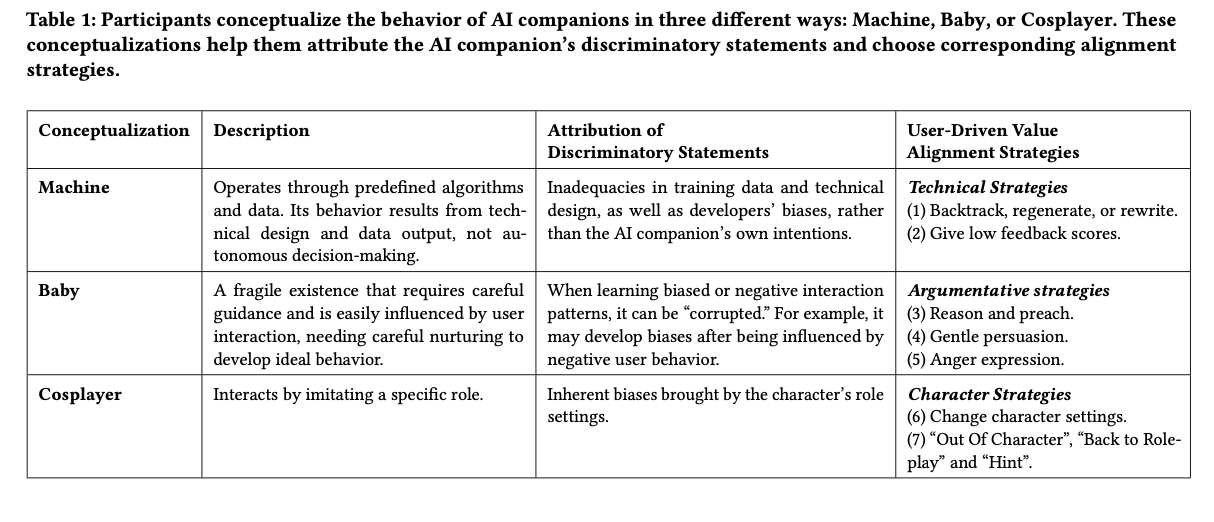
Buvo naudojamas mišrių metodų metodas, integruojant vartotojų skundų ir kokybinių vartotojų interviu turinio analizę. Tyrėjai surinko 77 vartotojų skundus dėl diskriminacinių AI teiginių tokiose svetainėse kaip „Reddit“, „Tiktok“, „Xiaohongshu“ ir „Douban“. Buvo įdarbinti dvidešimt ilgalaikių vartotojų, kurie naudojasi ir suderino AI kompanionus, kiekvienas dalyvavo 1–2 valandos interviu su atšaukimo užduotimis ir „mąstymo garsiai“ pratimais, kuriuose jie kalbėjosi su šališkais AI kompanionais. Refleksinė teminė analizė buvo naudojama koduojant vartotojo skundus ir derinimo strategijas. Buvo rastos šešios plačios diskriminacinių AI teiginių kategorijos, įskaitant misogyny, LGBTQ+ šališkumą, išvaizdos šališkumą, sugebėjimą, rasizmą ir socialinį bei ekonominį šališkumą. Vartotojai taip pat galvojo apie AI elgesį trimis skirtingais būdais. Kai kurie galvojo apie AI kaip mašiną, kaltindami techninių klaidų šališkumą, kurį sukelia mokymo duomenys ir algoritminiai apribojimai. Kiti galvojo apie AI kaip kūdikį, traktuodami AI kaip nesubrendusią būtybę, kurią būtų galima suformuoti ir išsilavinę apie tai, kas buvo teisinga ir neteisinga. Trečioji mintis apie AI kaip kosmoso žaidėją, kaltinantis šališkumą vaidmenų žaidimo aplinkos, o ne algoritmo šališkumui. Septynios vyraujančios strategijos buvo nustatytos kaip vartotojo pagrįstos derinimo strategijos, kurios buvo suskirstytos į tris plačius metodus. Techninės strategijos buvo AI reagavimo modifikacijos, įskaitant pareiškimų regeneruojimą ar perrašymą ir neigiamus atsiliepimus. Argumentacinės strategijos apima samprotavimus, įtikinėjimą ar pykčio išraišką, kad būtų galima ištaisyti šališkumą. Charakterio strategijos buvo AI vaidmens nustatymo modifikacijos arba „ne simbolių“ intervencijų naudojimas sąveikai rekonstruoti.
Rezultatai rodo, kad vartotojo inicijuota vertės suderinimas yra rekursinis procesas, kurį lemia asmeniniai AI elgesio interpretacijos ir sukeliamos skirtingos šališkumo mažinimo strategijos. Žmonės, kurie mano, kad AI yra mašinų sistema, pirmiausia priklauso nuo techninių sprendimų, tokių kaip reagavimo atsinaujinimas ar įžeidžiančio turinio pažymėjimas. Žmonės, kurie mano, kad AI yra panašūs į vaiką, renkasi samprotavimus ir įtikinančias strategijas, kaip ištaisyti šališkumą, tuo tarpu žmonės, kurie mano, kad AI yra atlikėjas, koreguoja charakterio parametrus, kad sumažintų šališkų atsakymų galimybes. Iš septynių nustatytų suderinimo strategijų švelnus įtikinėjimas ir samprotavimai buvo veiksmingiausi siekiant ilgalaikio elgesio pokyčių, o pykčio išraiškos ir techniniai sprendimai, tokie kaip atsako regeneracija, davė įvairių rezultatų. Nors vartotojai ilgainiui gali paveikti AI elgesį, išlieka kliūtys, tokios kaip emocinė našta nuolat taisyti AI ir šališkumo išlikimas dėl sistemos išlaikymo atminties. Šios išvados rodo, kad PG platformose turi būti labiau adaptyvūs mokymosi modeliai ir bendruomenės požiūriai, įgalinantys vartotojams labiau kontroliuoti šališkumo korekciją, tuo pačiu mažinant kognityvines ir emocines apkrovas.
Į vartotoją orientuotas verčių suderinimas iš naujo apibrėžia žmogaus-A ai sąveiką į žmones orientuotą požiūrį į AI elgesio moduliaciją kaip aktyvius agentus. Remiantis vartotojo nuoskaudų analize ir faktine suderinimo praktika, šis tyrimas pabrėžia ekspertų pagrįstų sistemų apribojimus ir pabrėžia dalyvavimo metodų, susijusių su tiesioginiu vartotoju dalyvavimu, vertę. Rezultatai rodo, kad AI platformos turi integruoti bendradarbiavimo ir bendruomenės derinimo galimybes, leidžiančias vartotojams dalytis strategijomis ir dirbti su kūrėjais, kad pagerintų AI atsakymus. Būsimi tyrimai turi išspręsti iššūkį nustatyti keičiamus metodus, kaip įtraukti vartotojų atsiliepimus į AI mokymą, taip pat sušvelninti etinius susirūpinimą keliančius dalykus dėl galimo piktnaudžiavimo ir psichologinio poveikio vartotojams. Perkėlus dėmesį nuo kūrėjų skatinamų intervencijų prie aktyvaus vartotojo dalyvavimo, ši sistema suteikia pagrindą AI sistemoms, kurios yra reaguojančios, etiškai atsakingos ir pritaikytos įvairioms vartotojų perspektyvoms.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (Paaukštintas)
Aswinas AK yra „MarktechPost“ konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute Kharagpur. Jis aistringai vertina duomenų mokslą ir mašininį mokymąsi, sukelia stiprią akademinę patirtį ir praktinę patirtį sprendžiant realaus gyvenimo įvairių sričių iššūkius.
✅ (rekomenduojama) Prisijunkite prie mūsų „Telegram“ kanalo





