
„Transformerio“ dėmesio mechanizmas beveik nepasikeitė nuo 2017 m. Dauguma efektyvumo darbų bandė visiškai pakeisti „softmax“ dėmesį. Naujas dokumentas eina kitu keliu. Jis išlaiko „softmax“ dėmesį ir priveržia koregavimo šaką.
Tyrėjų komanda iš Šiaurės Vakarų universiteto, Tilde Research ir Vašingtono universiteto pristato parametrizuotą vietinį linijinį dėmesį, vadinamą „Paralaksu“, kuris pritaikomas LLM išankstiniam mokymui ir kodiniams projektams su Muon.
Paralaksas nesiekia efektyvumo sumažindamas skaičiavimą. Jis sąmoningai prideda skaičiavimo, tada padaro tą skaičiavimą pigesnį naudoti naudojant šiuolaikinius GPU.
Kas yra paralaksas
„Paralax“ remiasi vietiniu linijiniu dėmesiu (LLA). LLA kyla iš bandymo laiko regresijos sistemos. Ši sistema skaito dėmesį kaip regresijos sprendimą, palyginti su raktų ir reikšmių poromis.
Šiuo požiūriu raktai yra mokymo duomenų taškai. Vertybės yra etiketės. Užklausa yra bandymo taškas. „Softmax“ dėmesys yra neparametrinis įvertis, vadinamas Nadaraya-Watson. Kiekvienai užklausai ji tinka vietinei pastoviajai funkcijai.
LLA atnaujina tą vietinį pastovų įvertinimą į vietinį tiesinį įvertinimą. Mokslininkų komanda įrodo, kad tai duoda griežtai mažesnę integruotą vidutinę kvadratinę paklaidą. Privalumas yra geresnis šališkumo ir dispersijos kompromisas asociatyviajai atminčiai.
Tačiau LLA turi didelių problemų. Norint tiksliai ją nukreipti, reikia išspręsti tiesinę sistemą kiekvienai užklausai. Tam naudojamas lygiagrečiojo konjuguoto gradiento (CG) sprendėjas. CG sprendėjas sukuria tris problemas: intensyvų įvestį / išvestį, sunkų reguliavimo ir išraiškingumo kompromisą ir mažo tikslumo nesuderinamumą.
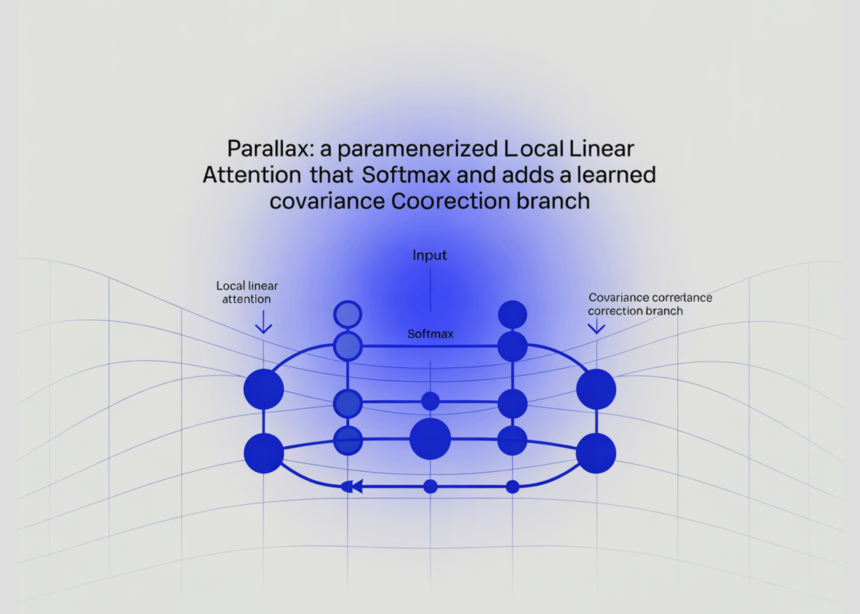
Paralaksas pašalina sprendiklį. Vietoj to, jis išmoksta papildomos projekcijos matricos. Tyrimo grupė tai rašo kaip ρi = WRxi. Čia WR yra išmokstama matrica, kuri tiria KV kovariaciją tiesiai iš sluoksnio įvesties.
Taigi „Paralax“ išlaiko vietinį tiesinį principą. Jis tiesiog pakeičia užklausos sprendimą išmoktu, į užklausą panašiu projektoriumi. Dėl to jis paprastesnis, efektyvesnis ir lengviau įgyvendinamas.
Kaip veikia mechanizmas
„Parallax“ formuluoja LLA kaip „softmax“ dėmesį ir papildomą korekciją. Rezultatas yra lygus softmax dėmesio išeigai, atėmus numatomą kovariacijos terminą. Tyrimo dokumente šis terminas yra KV kovariacija, padauginta iš išmokto zondo ρi.
Mokslininkų komanda taip pat atmeta vieną LLA gabalėlį, vadinamą ribiniu stiprinimo koeficientu, kuris nustatomas į nulį. Tai būtina stabilumui užtikrinti. Kai zondas yra parametrinis, pradinė geometrinė interpretacija nutrūksta. Jei veiksnys neįjungtas, mastelio keitimas gali skirtis arba ženklas apverstas.
Paralaksas yra dėmesio mechanizmų šeimoje. Tyrimo grupė juos suskirsto į tris ašis: pralaidumą, zondo konstrukciją ir afininę struktūrą. Vienu kraštutinumu „Parallax“ išsigimsta tiksliai iki „softmax“ dėmesio, kai zondo norma nukrenta iki nulio.
Nustatymas WR = 0 paralakso sluoksnis veikia taip pat, kaip softmax dėmesys. Taigi iš anksto paruoštą transformatoriaus kontrolinį tašką galima konvertuoti pridedant WR ir koreguoti.
Aparatūros argumentas
„Parallax“ paveldi „FlashAttention“ srautinio perdavimo struktūrą. Ji prideda vieną kovariacijos šaką, kuri pakartotinai naudoja tą patį rakto vertės srautą.
Tyrimo grupė išplečia pirmyn į dvi lygiagrečias balų atšakas. Abi šakos dalijasi internetiniu maksimumu, skalės keitimo koeficientu ir K bei V plytelėmis. Taigi „Parallax“ nereikia papildomo įvesties / išvesties vienai iteracijai.
Pagrindinė savybė yra didesnis aritmetinis intensyvumas (AI). AI yra slankiojo kablelio operacijų ir didelio pralaidumo atminties srauto santykis. Režimu, kuriame dominuoja KV darbas, paralaksas maždaug dvigubai padidina aritmetinį intensyvumą. Jis prideda skaičiavimo pakartotinai naudojant tą patį atminties srautą.
Tai nukreipia dėmesį į labiau skaičiavimo režimą. Būtent tokiu režimu branduolio optimizavimas padeda šiuolaikinėje aparatinėje įrangoje.
Tyrėjų komanda sukūrė dekodavimo branduolio prototipą CuTeDSL NVIDIA Hopper GPU. Hopper tensor core matmul instrukcijos veikia mažiausiai 64 eilučių plytelėse. Dekodavimo veiksmas pateikia tik vieną užklausos eilutę. Taigi QK ir RK produktai gali būti skaičiuojami kartu, laikantis instrukcijų, kuriose jau yra standartinio dėmesio.
Jie profiliavo su FlashAttention 2 ir 3 H200 GPU BF16 tikslumu. Jie keitė partijos dydžius nuo 1 iki 2 048, o kontekstinius ilgius – nuo 128 iki 32 768. Prototipas branduolys atitinka arba pranoksta FlashAttention visose konfigūracijose. Žemiau pateiktame paveikslėlyje nurodomas 1,54 × greičio padidėjimas pagal skaičiavimo suderintą nustatymą ir 1,14 × įvesties / išvesties suderinimo parametras.

Ką rodo eksperimentai
Tyrimo grupė patvirtino Parallax sintetinėms užduotims ir LLM išankstiniam mokymui 0,6 B ir 1, 7 B skalėmis. Modeliai naudojo Qwen-3 architektūrą „torchtitan“ saugykloje. Jie mokėsi naudotis Ultra-FineWeb duomenų rinkiniu, kurio konteksto ilgis yra 4096. Pradinės linijos apėmė „softmax“ dėmesį („Transformer“, „Mamba“, „Gated DeltaNet“, „MesaNet“ ir „Kimi DeltaAttention“.
Pagal MAD-Benchmark Parallax pasiekė aukščiausią bendrą tikslumą – 0,716 vidurkį. Tai nuosekliai tobulino į atšaukimą orientuotas užduotis, tokias kaip kontekstinis atšaukimas ir atrankinis kopijavimas. Jis išliko konkurencingas atliekant suspaudimo ir įsiminimo užduotis.
Kalbant apie kalbos modeliavimą, Parallax with Muon pasiekė geriausią sumišimą abiem skalėmis. Jis taip pat užfiksavo didžiausią vidutinį pasroviui skirtą tikslumą. Esant 1,7B, Parallax vidutiniškai surinko 62,45 balo, o Transformerio 61,43.
Dvi valdikliai tikrina, iš kur gaunamas padidėjimas. Parametrus suderintas transformatorius užpildė tik nedidelę tarpo dalį. Skaičiavimu suderintas „Parallax“ vis tiek įveikė abi bazines linijas. Straipsnyje teigiama, kad tai nurodo patį mechanizmą, o ne papildomus parametrus ar skaičiavimą.
Optimizavimo priemonės posūkis
Pagrindinė išvada yra optimizatoriaus ir architektūros sąveika. Paralaksas rodo didelį pranašumą esant Muonui. Valdant AdamW pranašumas pastebimai susitraukia arba net išnyksta.
Muon yra naujausias paslėptų sluoksnių matricos parametrų optimizatorius. Jis naudoja impulso buferio polinį koeficientą, todėl atnaujinimų sąlyga yra lygiai viena. Ankstesnis darbas rodo, kad tai sukuria geriau kondicionuotas svorio matricas.
Straipsnyje tyrimo grupė atskleidė spragą iki pataisos šakos. Jie apibrėžia korekcijos ir išvesties santykį (COR). Pagal Muoną giliausiuose sluoksniuose COR viršija 8. Pagal AdamW jis lieka žemiau 4.
WR projekcija yra neproporcingai paveikta. Jo stabilus rangas žlunga valdant AdamW, bet išlieka aukštas valdant Muonui. Vartojimo eksperimentas patvirtina modelį. Pagal AdamW modelis išmoksta nuslopinti korekcijos šaką, o ne ją naudoti.
Mokslininkų komanda tai vadina pirmuoju empiriniu stipraus dėmesio mechanizmų architektūros optimizavimo kodo projektavimo demonstravimu. Jie netvirtina, kad Muonas su WSD yra optimalus receptas. Apendikso abliacija rodo, kad pranašumas mažėja irimo fazės metu.
Kaip skiriasi balai
„Parallax“ taip pat sukuria skirtingus balų pasiskirstymus iš „softmax“ dėmesio. Jo vieno žetono svoriai gali būti neigiami ir viršyti vieną dydį. Standartiniai softmax svoriai to negali padaryti.
Tyrimo grupė praneša apie tris efektus. Paralaksas gali aktyviai atimti vertės komponentus iš nesusijusių žetonų. Tai žymiai sumažina dėmesio pritraukimą pirmuoju žetonu. Jo bazinė softmax entropija išlieka didesnė, todėl dėmesys sutelkiamas labiau.
Stiprybės ir trūkumai bei atviri klausimai
Stiprybės
- Išlaiko „softmax“ dėmesį, todėl iš anksto apmokytas transformatorius gali konvertuoti pridėdamas WR ir patikslindamas.
- Pakartotinai naudojant „FlashAttention“ rakto vertės srautą, per iteraciją nepridedama jokio papildomo įvesties / išvesties.
- Padvigubina aritmetinį intensyvumą, o branduolio prototipas atitinka arba pranoksta FlashAttention 2/3 dekodavimo srityje.
- Rodo nuoseklų sumišimą ir pasroviui skirtus pranašumus, kai valdikliai atitinka parametrus ir skaičiavimus.
Trūkumai ir atviri klausimai
- Pelnas labai priklauso nuo Muono; valdant AdamW pranašumas iš esmės išnyksta.
- Tiksli priklausomybės nuo optimizatoriaus priežastis lieka atviras klausimas.
- Rezultatai sustoja ties 1,7 B mastu, be MoE, ilgesnio konteksto ar didesnių paleidimų.
- Privalumas sumažėja WSD skilimo fazės metu, tik iš dalies fiksuojamas atkaitinant svorį.
Key Takeaways
- „Paralax“ išlaiko „softmax“ dėmesį ir prideda išmoktą kovariacijos korekcijos šaką, pakeičiančią LLA konjuguoto gradiento sprendiklį užklausai.
- Jis padvigubina aritmetinį intensyvumą, pakartotinai naudojant tą patį KV srautą, o dekodavimo branduolys atitinka arba įveikia FlashAttention 2/3.
- Nuolatinis sumišimas ir 0,6 B ir 1,7 B padidėjimas pasroviui, naudojant parametrų suderinimo ir skaičiavimo valdiklius.
- Pelnas labai priklauso nuo Muono; pagal AdamW pranašumas pastebimai susitraukia arba išnyksta.
- Nustatymas WR = 0 tiksliai atkuria softmax dėmesį, todėl iš anksto apmokyti transformatoriai gali konvertuoti pridėdami WR ir koreguodami.
Patikrinkite Popierius ir Repo. Be to, nedvejodami sekite mus Twitter ir nepamirškite prisijungti prie mūsų 150 000+ ML SubReddit ir Prenumeruoti mūsų naujienlaiškis. Palauk! ar tu telegramoje? dabar galite prisijungti prie mūsų ir per telegramą.
Norite bendradarbiauti su mumis reklamuodami savo „GitHub Repo“ ARBA „Huging Face“ puslapį, išleisdami produktą ARBA internetinį seminarą ir pan.? Susisiekite su mumis






