

Didelės kalbos modeliai parodė nepaprastas problemų sprendimo galimybes ir matematinius bei loginius samprotavimus. Šie modeliai buvo pritaikyti sudėtingoms samprotavimo užduotims, įskaitant tarptautinę matematikos olimpiados (TJO) kombinatorijos problemas, abstrakcijos ir samprotavimo korpuso (ARC) galvosūkius ir paskutinį žmonijos egzamino (HLE) klausimus. Nepaisant patobulinimų, esami AI modeliai dažnai kovoja su aukšto lygio problemų sprendimu, kuriam reikalingas abstraktus samprotavimas, oficialus patikrinimas ir pritaikomumas. Didėjanti AI orientuoto problemų sprendimo paklausa paskatino tyrėjus sukurti naujus išvadų metodus, kurie sujungia kelis metodus ir modelius, siekiant padidinti tikslumą ir patikimumą.
PG samprotavimų iššūkis yra sprendimų teisingumo patikrinimas, ypač matematinėms problemoms, reikalaujančioms kelių žingsnių ir loginių dedukcijų. Tradiciniai modeliai gerai veikia tiesmukiškai aritmetikoje, tačiau kovoja, kai susiduria su abstrakčiomis sąvokomis, oficialiais įrodymais ir aukšto matmens samprotavimais. Veiksminga AI sistema turi generuoti galiojančius sprendimus, laikydamasis nustatytų matematinių principų. Dabartiniai apribojimai paskatino tyrėjus ištirti išplėstinius išvadų metodus, kurie pagerina patikrinimą ir pagerina problemų sprendimo patikimumą.
Buvo įdiegta keletas metodų, skirtų spręsti matematinius samprotavimo iššūkius. „Zero-Shot“ mokymasis leidžia modeliams išspręsti problemas be išankstinio ekspozicijos, tuo tarpu geriausia iš „-N“ atranka pasirenka tiksliausią sprendimą iš kelių sugeneruotų atsakymų. „Monte Carlo Tree Search“ (MCTS) tiria galimus sprendimus modeliuojant, o teoremų teikimo programinė įranga, tokia kaip Z3, padeda patikrinti loginius teiginius. Nepaisant jų naudingumo, šiems metodams dažnai trūksta patikimumo, kai susiduria su sudėtingomis problemomis, reikalaujančiomis struktūrizuoto patikrinimo. Šis atotrūkis paskatino sukurti išsamesnę sistemą, kurioje būtų integruotos kelios išvados strategijos.
Tyrėjų komanda iš Bostono universiteto, „Google“, Kolumbijos universiteto, MIT, Intuit ir Stanford pristatė novatorišką požiūrį, kuriame derinami įvairūs išvadų metodai su automatiniu patikrinimu. Tyrimas integruoja bandymo laiko modeliavimą, sustiprinimo mokymąsi ir meta-mokymąsi, kad padidintų samprotavimo rezultatus. Pasinaudojant keliais modeliais ir problemų sprendimo metodikomis, metodas užtikrina, kad PG sistemos nėra priklausomos nuo vienos technikos, taigi padidėja tikslumas ir pritaikomumas. Sistema naudoja struktūrizuotus agentų grafikus, kad patobulintų problemų sprendimo kelius ir pakoreguotų išvadų strategijas, pagrįstas užduoties sudėtingumu.
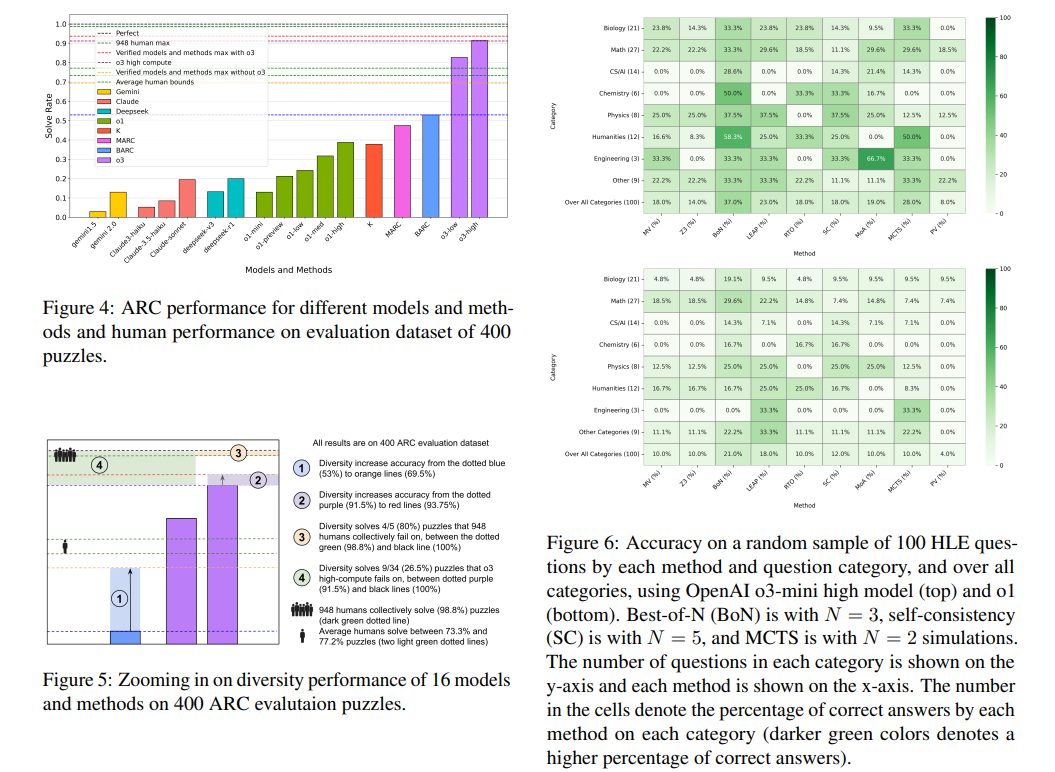
Metodika sukasi apie matematinių ir loginių problemų sprendimų patikrinimą atliekant automatinius patikrinimus. TJO problemomis tyrėjai įdiegė aštuonis skirtingus metodus, įskaitant LEAP, Z3, Monte Carlo medžių paiešką ir plano paiešką, kad anglų kalbos pagrįsti sprendimai būtų paversti oficialiais įrodymais „Lean Theorem“ pateiktoje aplinkoje. Tai leidžia absoliučiai patikrinti teisingumą. ARC galvosūkiai nagrinėjami naudojant sintezuotus kodo sprendimus, patvirtintus atliekant vieneto bandymus su mokymo pavyzdžiais. HLE klausimai, susiję su platesnėmis samprotavimų kategorijomis, pasinaudoja geriausiu „-n“ atrankos, kaip netobulu tikrintoju, siekiant pagerinti sprendimų pasirinkimą. Stiprinimo mokymasis ir bandymo laikas Meta-mokymasis patikslina išvadų procesą, koreguojant agento grafiko atvaizdus, remiantis ankstesniu problemų sprendimo rezultatais.
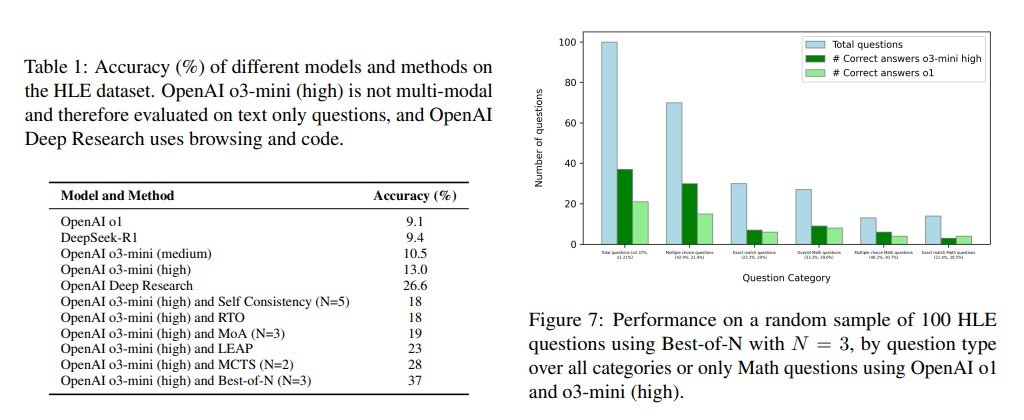
Šio požiūrio atlikimas parodė esminį patobulinimą atliekant įvairias samprotavimo užduotis. TJO kombinatorinių vaistų problemos tikslumas padidėjo nuo 33,3% iki 77,8%, parodant reikšmingą AI galimybių šuolį matematiniams įrodiniams generavimui. Kalbant apie HLE klausimus, tikslumas padidėjo nuo 8% iki 37%, tai rodo padidėjusį problemų sprendimo pritaikomumą įvairiose disciplinose. ARC galvosūkiai, žinomi dėl savo sudėtingumo, parodė 80% sėkmės procentą dėl anksčiau neišspręstų problemų, kurias bandė 948 dalyviai. Be to, modelis sėkmingai išsprendė 26,5% lanko galvosūkių, kuriems nepavyko išspręsti „Openai“ O3 didelio komputelio modelio. Tyrimas pabrėžia kelių išvadų modelių derinimo efektyvumą, parodant, kad suvestinės metodikos pralenkia vieno metodo metodus atliekant sudėtingų samprotavimo užduotis.
Šis tyrimas pateikia transformacinę pažangą AI pagrįstame samprotavime, sujungiant įvairias išvadų strategijas su automatinėmis patikrinimo sistemomis. Pasinaudojus keliais AI metodais ir optimizuojant samprotavimo būdus per stiprinimo mokymąsi, tyrimas siūlo keičiamą sprendimą sudėtingiems problemų sprendimo iššūkiams. Rezultatai rodo, kad AI sistemos našumą galima žymiai sustiprinti per struktūrizuotą išvadų kaupimą, ateityje atverti kelią sudėtingesniems samprotavimo modeliams. Šis darbas prisideda prie platesnio AI pritaikymo matematinio problemų sprendimo ir loginio patikrinimo, sprendžiant pagrindinius iššūkius, kurie apribojo AI veiksmingumą atliekant pažangias samprotavimo užduotis.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama „Read-LG AI Research“ išleidžia „Nexus“: pažangių sistemos integracinių agentų AI sistemos ir duomenų atitikties standartų, skirtų teisiniams klausimams spręsti AI duomenų rinkiniuose
Nikhil yra „MarkTechPost“ stažuotės konsultantas. Jis siekia integruoto dvigubo laipsnio medžiagų Indijos technologijos institute, Kharagpur mieste. „Nikhil“ yra AI/ML entuziastas, kuris visada tiria programas tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagos mokslo patirtį, jis tyrinėja naujus pasiekimus ir sukuria galimybes prisidėti.






