

Po didelių kalbų modelių (LLMS) sėkmės dabartiniai tyrimai apima ne tik teksto supratimą, bet ir daugiamodalinius samprotavimo užduotis. Šios užduotys integruoja viziją ir kalbą, kuri yra būtina dirbtiniam bendram intelektui (AGI). Kognityviniai etalonai, tokie kaip „PuzzleVQA“ ir „AlgopuPleVQA“, įvertina AI gebėjimą apdoroti abstrakčią vaizdinę informaciją ir algoritminius pagrindus. Net ir pasiekus pažangą, LLM kovoja su multimodaliniais samprotavimais, ypač modelių atpažinimu ir erdviniu problemų sprendimu. Didelės skaičiavimo išlaidos sukelia šiuos iššūkius.
Ankstesni vertinimai rėmėsi simboliniais etalonais, tokiais kaip ARC-AGI, ir vaizdinius vertinimus, tokius kaip Raveno progresyvios matricos. Tačiau jie nepakankamai užginčija AI gebėjimą apdoroti multimodalinius įvestis. Neseniai buvo įvesti duomenų rinkiniai, tokie kaip „PuzzleVQA“ ir „AlgopuzleVQA“, siekiant įvertinti abstrakčius vaizdinius samprotavimus ir algoritminius problemų sprendimą. Šiems duomenų rinkiniams reikalingi modeliai, integruoti vaizdinį suvokimą, loginį dedukciją ir struktūrizuotus samprotavimus. Nors ankstesni modeliai, tokie kaip GPT-4-Turbo ir GPT-4O, parodė patobulinimus, jie vis tiek susidūrė su abstrakčių samprotavimų ir multimodalinio aiškinimo apribojimais.
Singapūro technologijos ir projektavimo universiteto (SUTD) tyrėjai įvedė sistemingą Openai GPT- (N) ir O- (N) modelių serijų, susijusių su multimodalinio dėlionės sprendimo užduotimis, įvertinimą. Jų tyrimas ištyrė, kaip pagrįstų galimybių gebėjimai vystėsi įvairiose modelio kartose. Tyrimo tikslas buvo nustatyti AI suvokimo, abstrakčių samprotavimo ir problemų sprendimo įgūdžių spragas. Komanda palygino modelių, tokių kaip „GPT-4-Turbo“, „GPT-4O“ ir „O1“, našumą „PuzzleVQA“ ir „AlgopuPleVQA“ duomenų rinkiniuose, įskaitant abstrakčius vaizdinius galvosūkius ir algoritminius samprotavimo iššūkius.
Tyrėjai atliko struktūrizuotą vertinimą, naudodamiesi dviem pirminiais duomenų rinkiniais:
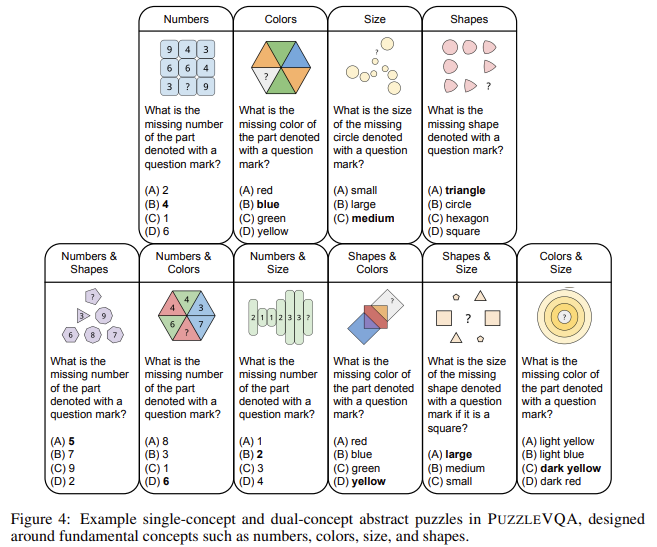
- „PuzzleVQA“: „PuzzleVQA“ daugiausia dėmesio skiria abstrakčiam vaizdiniam samprotavimui ir reikalauja, kad modeliai atpažintų skaičių, formų, spalvų ir dydžių modelius.
- „AlgopuzzleVQA“: „AlgopuzzleVQA“ pateikia algoritmines problemų sprendimo užduotis, reikalaujančias loginio dedukcijos ir skaičiavimo pagrindimo.
Vertinimas buvo atliktas naudojant tiek kelių pasirinkimų, tiek atvirus klausimų formatus. Tyrime buvo naudojama minties grandinė (COT), paskatinusi samprotavimus, ir išanalizavo našumo kritimą pereinant iš atsakymų į atsakymus į atsakymus į atsakymus į atsakymus. Modeliai taip pat buvo tiriami tokiomis sąlygomis, kai regos suvokimas ir indukciniai samprotavimai buvo pateikti atskirai diagnozuoti konkrečias silpnybes.
Tyrime pastebėtas nuolatinis pagrindimo galimybių pagerėjimas įvairiose modelio kartose. „GPT-4o“ parodė geresnį našumą nei „GPT-4-Turbo“, o O1 pasiekė ryškiausius pasiekimus, ypač atliekant algoritminius pagrindimo užduotis. Tačiau šis pelnas labai padidėjo skaičiavimo išlaidų padidėjimu. Nepaisant bendros pažangos, AI modeliai vis dar kovojo su užduotimis, kurioms reikėjo tikslaus vizualinio aiškinimo, pavyzdžiui, atpažinti trūkstamų formų ar iššifruoti abstrakčius modelius. Nors O1 gerai veikė skaitmeniniais samprotavimais, jam buvo sunku tvarkyti formą pagrįstus galvosūkius. Tikslumo skirtumas tarp kelių ir neterminuotų užduočių tikslumo parodė stiprią priklausomybę nuo atsakymų raginimų. Be to, suvokimas išliko dideliu visų modelių iššūkiu, nes tikslumas žymiai pagerėjo, kai buvo pateikta aiškios vizualinės detalės.
Greitai pakartojant darbą galima apibendrinti keliuose išsamiuose taškuose:
- Tyrimas pastebėjo reikšmingą pagrindimo galimybių padidėjimą nuo GPT-4-Turbo iki GPT-4O ir O1. Nors „GPT-4o“ padidėjo vidutinio sunkumo, perėjimas prie O1 padidino pagerėjimą, tačiau skaičiavimo sąnaudas padidėjo 750x, palyginti su GPT-4O.
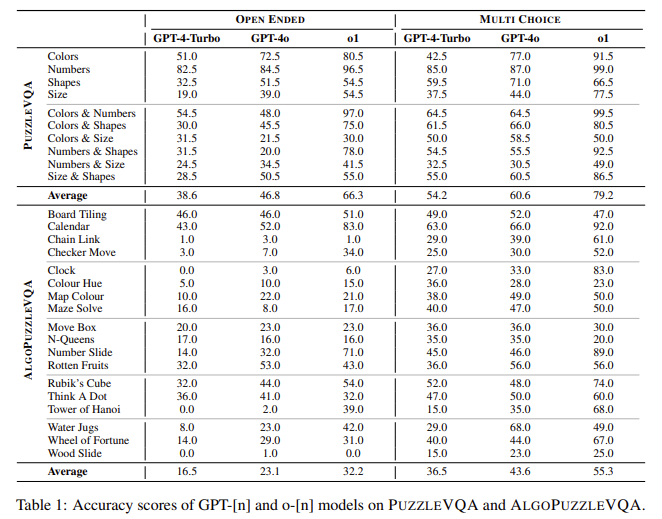
- „PULLESTVQA“ per „PuzzleVQA“ O1 pasiekė vidutinį 79,2% tikslumą atsakinguose su atsakymų variantais, pranokdamas GPT-4o 60,6% ir GPT-4-Turbo 54,2%. Tačiau atliekant neterminuotas užduotis, visi modeliai demonstravo našumo kritimą: O1 įvertino 66,3%, GPT-4O-46,8%, o GPT-4-Turbo-38,6%.
- „AlgopuzzeVQA“ O1 iš esmės pagerėjo ankstesniuose modeliuose, ypač dėlionėse, kurioms reikalingas skaitmeninis ir erdvinis atskaitymas. O1 surinko 55,3%, palyginti su 43,6% GPT-4O ir „GPT-4-Turbo“ 36,5% užduočių su atsakymų variantais. Tačiau jo tikslumas sumažėjo 23,1% atliekant neterminuotas užduotis.
- Tyrimas nustatė, kad suvokimas yra pagrindinis visų modelių apribojimas. Įšvirkškite aiškias vaizdines detales pagerinęs tikslumą 22–30%, tai rodo priklausomybę nuo išorinio suvokimo AIDS. Indukcinių samprotavimų gairės dar labiau padidino našumą 6–19%, ypač skaitmeniniu ir erdviniu modelio atpažinimu.
- O1 pasižymėjo skaitmeniniais samprotavimais, tačiau kovojo su formos galvosūkiais, parodydamas 4,5% kritimą, palyginti su GPT-4o formos atpažinimo užduotimis. Be to, jis gerai sekėsi struktūrizuotai problemų sprendimui, tačiau susidūrė su iššūkiais atvirais scenarijais, reikalaujančiais savarankiško išskaičiavimo.
Patikrinkite Popieriaus ir „GitHub“ puslapis. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (Paaukštintas)
„MarktechPost“ ir „IIT Madras“ dvigubo laipsnio studentė konsultacinė Sana Hassan aistringai taiko technologijas ir AI, kad galėtų spręsti realaus pasaulio iššūkius. Turėdamas didelį susidomėjimą išspręsti praktines problemas, jis pateikia naują perspektyvą AI ir realaus gyvenimo sprendimų sankryžai.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo






