„Robbyant“, „Ant Group“ įkūnytas AI padalinys, turi atvirojo kodo „LingBot-World“ – didelio masto pasaulio modelį, kuris vaizdo įrašų generavimą paverčia interaktyviu simuliatoriumi, skirtu įkūnytiems agentams, autonominiam vairavimui ir žaidimams. Sistema sukurta taip, kad būtų sukurta valdoma aplinka, pasižyminti dideliu vaizdo tikslumu, stipria dinamika ir ilgu laiko horizontu, išlaikant pakankamai jautrią valdymą realiuoju laiku.
Nuo teksto iki vaizdo įrašo iki teksto į pasaulį
Dauguma teksto į vaizdo įrašą modelių sukuria trumpus klipus, kurie atrodo tikroviški, bet elgiasi kaip pasyvūs filmai. Jie nemodeliuoja, kaip veiksmai keičia aplinką laikui bėgant. LingBot-World yra sukurtas kaip veiksmo sąlygotas pasaulio modelis. Jis mokosi virtualaus pasaulio perėjimo dinamikos, kad klaviatūros ir pelės įvestis kartu su fotoaparato judesiu paskatintų būsimų kadrų evoliuciją.
Formaliai modelis išmoksta sąlyginį būsimų vaizdo žetonų paskirstymą, atsižvelgiant į praeities kadrus, kalbos raginimus ir atskirus veiksmus. Treniruotės metu jis numato sekas iki maždaug 60 sekundžių. Išvados metu jis gali automatiškai regresyviai skleisti nuoseklius vaizdo srautus, kurie tęsiasi iki maždaug 10 minučių, išlaikant stabilią scenos struktūrą.
Duomenų variklis, nuo žiniatinklio vaizdo įrašų iki interaktyvių trajektorijų
Pagrindinis „LingBot-World“ dizainas yra vieningas duomenų variklis. Ji suteikia išsamią, suderintą priežiūrą, kaip veiksmai keičia pasaulį ir apima įvairias tikras scenas.
Duomenų rinkimo dujotiekis sujungia 3 šaltinius:
- Didelio masto žiniatinklio vaizdo įrašai apie žmones, gyvūnus ir transporto priemones iš pirmojo ir trečiojo asmens peržiūrų
- Žaidimo duomenys, kur RGB kadrai yra griežtai susieti su vartotojo valdikliais, tokiais kaip W, A, S, D ir fotoaparato parametrais
- Sintetinės trajektorijos, perteiktos Unreal Engine, kur žinomi švarūs kadrai, kameros vidinės ir išorinės savybės bei objektų išdėstymai
Po surinkimo profiliavimo etapas standartizuoja šį nevienalytį korpusą. Jis filtruoja skiriamąją gebą ir trukmę, suskirsto vaizdo įrašus į klipus ir įvertina trūkstamus fotoaparato parametrus, naudodamas geometrijos ir pozos modelius. Vaizdo kalbos modelis įvertina klipų kokybę, judesio dydį ir vaizdo tipą, tada pasirenka kuruojamą poaibį.
Be to, hierarchinis antraščių modulis sukuria 3 teksto priežiūros lygius:
- Pasakojimo antraštės visoms trajektorijoms, įskaitant fotoaparato judėjimą
- Scenos statiniai antraštės, apibūdinančios aplinkos išdėstymą be judesio
- Tankios trumpalaikės antraštės, skirtos vietos dinamikai
Šis atskyrimas leidžia modeliui atskirti statinę struktūrą nuo judėjimo modelių, o tai svarbu norint užtikrinti ilgo horizonto nuoseklumą.
Architektūra, Vidaus reikalų ministerijos vaizdo pagrindas ir veiksmų kondicionavimas
LingBot-World prasideda nuo Wan2.2, 14B parametro vaizdo iki vaizdo difuzijos transformatoriaus. Šis pagrindas jau fiksuoja stiprius atviro domeno vaizdo įrašus. Robbyant komanda ją išplečia į DiT ekspertų mišinį su 2 ekspertais. Kiekvienas ekspertas turi apie 14B parametrų, taigi bendras parametrų skaičius yra 28B, tačiau kiekviename triukšmo slopinimo etape aktyvus tik 1 ekspertas. Dėl to išvadų kaina yra panaši į tankų 14B modelį, tuo pačiu padidinant pajėgumus.
Mokymo programa prailgina treniruočių sekas nuo 5 sekundžių iki 60 sekundžių. Tvarkaraštis padidina didelio triukšmo laiko žingsnių dalį, o tai stabilizuoja visuotinius išdėstymus ilguose kontekstuose ir sumažina režimo sutraukimą ilgo išleidimo metu.
Kad modelis būtų interaktyvus, veiksmai įpurškiami tiesiai į transformatoriaus blokus. Kameros apsisukimai yra užkoduoti Plücker įterpimais. Klaviatūros veiksmai vaizduojami kaip keli aktyvūs vektoriai virš klavišų, tokių kaip W, A, S, D. Šios koduotės sujungiamos ir perduodamos per adaptyvaus sluoksnio normalizavimo modulius, kurie moduliuoja paslėptas DiT būsenas. Tiksliai sureguliuoti tik veiksmo adapterio sluoksniai, pagrindinis vaizdo įrašo pagrindas lieka užšaldytas, todėl modelis išlaiko vaizdo kokybę nuo išankstinio mokymo, mokydamasis reagavimo į veiksmus iš mažesnio interaktyvaus duomenų rinkinio.
Mokymuose naudojamos tiek vaizdo į vaizdo įrašą, tiek vaizdo įrašo tęsinio užduotys. Atsižvelgiant į vieną vaizdą, modelis gali susintetinti būsimus kadrus. Dalinis klipas gali pratęsti seką. Dėl to atsiranda vidinė perėjimo funkcija, kuri gali prasidėti nuo savavališkų laiko taškų.
LingBot World Fast, distiliavimas realiu laiku
Vidutiniškai apmokytas modelis „LingBot-World Base“ vis dar priklauso nuo kelių žingsnių sklaidos ir visiško laiko dėmesio, o tai yra brangi sąveika realiuoju laiku. Robbyant komanda pristato LingBot-World-Fast kaip pagreitintą variantą.
Greitas modelis inicijuojamas didelio triukšmo eksperto ir pakeičia visą laikiną dėmesį blokiniu priežastiniu dėmesiu. Kiekvieno laikinojo bloko viduje dėmesys yra dvikryptis. Visuose blokuose tai yra priežastinis ryšys. Šis dizainas palaiko pagrindinių verčių kaupimą talpykloje, todėl modelis gali automatiškai regresyviai transliuoti kadrus su mažesnėmis sąnaudomis.
Distiliuojant naudojama difuzijos priverstinė strategija. Mokinys yra apmokytas naudoti nedidelį tikslinių laiko žingsnių rinkinį, įskaitant 0 laiko žingsnį, todėl jis mato ir triukšmingus, ir švarius latentus. Paskirstymo suderinimas Distiliavimas derinamas su priešinga diskriminatoriaus galvute. Rungtynių pralaimėjimas atnaujina tik diskriminatorių. Studentų tinklas atnaujinamas naudojant distiliavimo nuostolius, kurie stabilizuoja mokymą, išsaugant veiksmų seką ir laikiną darną.
Eksperimentų metu „LingBot World Fast“ pasiekia 16 kadrų per sekundę, kai apdoroja 480p vaizdo įrašus sistemoje su 1 GPU mazgu, ir palaiko sąveikos delsą iki galo iki 1 sekundės, kad būtų galima valdyti realiuoju laiku.
Atsirandanti atmintis ir ilgas elgesys
Viena iš įdomiausių LingBot-World savybių yra atsirandanti atmintis. Modelis išlaiko visuotinį nuoseklumą be aiškių 3D vaizdų, tokių kaip Gauso dėmės. Kai fotoaparatas nutolsta nuo orientyro, pvz., Stounhendžo, ir grįžta maždaug po 60 sekundžių, struktūra vėl pasirodo su nuoseklia geometrija. Kai automobilis išvažiuoja iš rėmo ir vėliau vėl įvažiuoja, jis pasirodo fiziškai tikėtinoje vietoje, neužšalęs ir nenustatytas iš naujo.
Modelis taip pat gali išlaikyti itin ilgas sekas. Tyrimo grupė rodo nuoseklų vaizdo įrašų generavimą, kuris trunka iki 10 minučių, su stabiliu išdėstymu ir pasakojimo struktūra.)
VBench rezultatai ir palyginimas su kitais pasaulio modeliais
Kiekybiniam įvertinimui tyrimų grupė naudojo „VBench“ kuruojamame 100 sugeneruotų vaizdo įrašų rinkinyje, kurių kiekvienas buvo ilgesnis nei 30 sekundžių. LingBot-World lyginamas su 2 naujausiais pasaulio modeliais, Yume-1.5 ir HY-World-1.5.
„VBench“ svetainėje „LingBot World“ praneša:
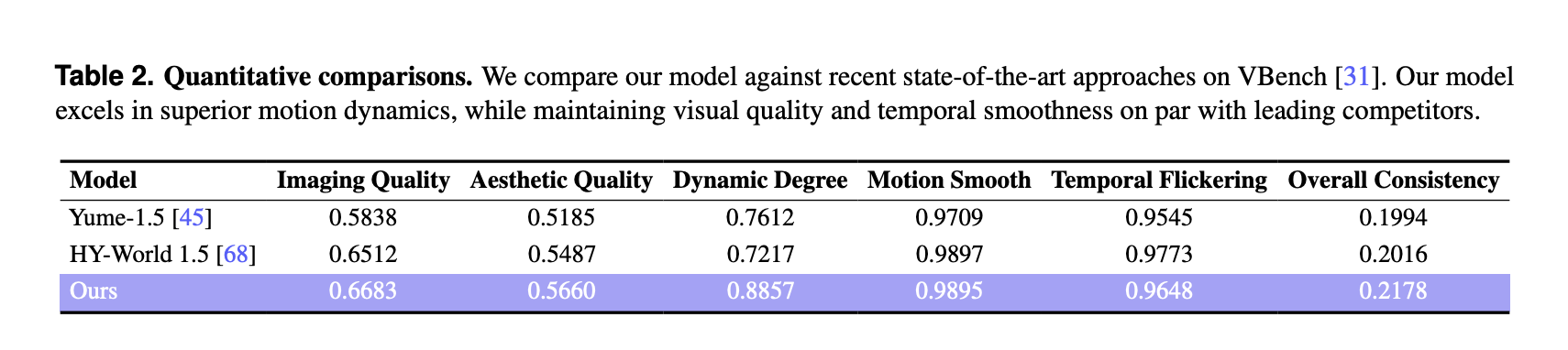
Šie balai yra aukštesni už abu pradinius vaizdo kokybės, estetinės kokybės ir dinaminio laipsnio rodiklius. Dinaminė laipsnio riba yra didelė – 0,8857, palyginti su 0,7612 ir 0,7217, o tai rodo sodresnius scenos perėjimus ir sudėtingesnį judesį, reaguojantį į vartotojo įvestį. Judesio sklandumas ir laikinas mirgėjimas yra palyginami su geriausia bazine linija, o metodas pasiekia geriausią bendrą nuoseklumo metriką tarp 3 modelių.
Atskiras palyginimas su kitomis interaktyviosiomis sistemomis, tokiomis kaip Matrix-Game-2.0, Mirage-2 ir Genie-3, rodo, kad LingBot-World yra vienas iš nedaugelio visiškai atvirojo kodo pasaulio modelių, kuris sujungia bendrą domeno aprėptį, ilgą generavimo horizontą, aukštą dinaminį laipsnį, 720p raišką ir realiojo laiko galimybes.

Programos, suaktyvinami pasauliai, agentai ir 3D rekonstrukcija
Be vaizdo sintezės, „LingBot-World“ yra įkūnyto AI bandymo vieta. Modelis palaiko greitus pasaulio įvykius, kai tekstinės instrukcijos keičia orą, apšvietimą, stilių arba laikui bėgant įkvepia vietinius įvykius, tokius kaip fejerverkai ar judantys gyvūnai, išsaugant erdvinę struktūrą.
Jis taip pat gali mokyti tolesnius veiksmų agentus, pavyzdžiui, naudojant mažą vizijos kalbos veiksmų modelį, pvz., Qwen3-VL-2B, numatantį valdymo politiką iš vaizdų. Kadangi sugeneruoti vaizdo srautai yra geometriškai nuoseklūs, jie gali būti naudojami kaip įvestis į 3D rekonstrukcijos vamzdynus, kurie sukuria stabilius taškų debesis patalpų, lauko ir sintetinėms scenoms.
Raktai išsinešti
- LingBot-World yra veiksmo sąlygotų pasaulio modelis, kuris išplečia tekstą į vaizdo įrašą į teksto ir pasaulio modeliavimą, kuriame klaviatūros veiksmai ir kameros judesys tiesiogiai valdo ilgo horizonto vaizdo įrašų išleidimą iki maždaug 10 minučių.
- Sistema parengta naudojant vieningą duomenų variklį, kuris sujungia žiniatinklio vaizdo įrašus, žaidimų žurnalus su veiksmo etiketėmis ir „Unreal Engine“ trajektorijomis, taip pat hierarchinį pasakojimą, statinę sceną ir tankias laiko antraštes, kad atskirtų išdėstymą nuo judesio.
- Pagrindinis pagrindas yra 28B parametrų ekspertų difuzijos transformatoriaus, pagaminto iš Wan2.2, su 2 ekspertais po 14B, ir veiksmo adapterių, kurie yra tiksliai sureguliuoti, kol vizualinis pagrindas lieka užšaldytas, mišinys.
- „LingBot-World-Fast“ yra distiliuotas variantas, kuriame naudojamas blokinis priežastinis dėmesys, difuzijos priverstinis ir paskirstymo suderinimo distiliavimas, kad būtų pasiekta maždaug 16 kadrų per sekundę 480p raiška 1 GPU mazge, o interaktyviam naudojimui pranešama, kad vėlavimas nuo pabaigos iki pabaigos yra mažesnis nei 1 sekundė.
- „VBench“ su 100 sugeneruotų vaizdo įrašų, ilgesnių nei 30 sekundžių, „LingBot-World“ praneša apie aukščiausią vaizdo kokybę, estetinę kokybę ir dinaminį laipsnį tarp „Yume-1.5“ ir „HY-World-1.5“, o modelis rodo atsirandančią atmintį ir stabilią ilgo nuotolio struktūrą, tinkamą įkūnytiems agentams ir 3D rekonstrukcijai.
Patikrinkite Popierius, atpirkimas, projekto puslapis ir modelio svoriai. Be to, nedvejodami sekite mus Twitter ir nepamirškite prisijungti prie mūsų 100 000+ ML SubReddit ir Prenumeruoti mūsų naujienlaiškis. Palauk! ar tu telegramoje? dabar galite prisijungti prie mūsų ir per telegramą.