

Dideli kalbų modeliai (LLM), tokie kaip GPT, Dvyniai ir Claude, naudoja didžiulius mokymo duomenų rinkinius ir sudėtingas architektūras, kad sukurtų aukštos kokybės atsakymus. Tačiau optimizavus jų skaičiavimo laiką, išlieka sudėtinga, nes padidėjęs modelio dydis sukelia didesnes skaičiavimo išlaidas. Tyrėjai ir toliau tyrinėja strategijas, kurios maksimaliai padidina efektyvumą išlaikant ar gerindami modelio našumą.
Vienas plačiai pritaikytas LLM našumo gerinimo būdas yra ansamblis, kai keli modeliai sujungiami, kad būtų sukurtas galutinis išvestis. Agentų mišinys (MOA) yra populiarus ansamblio metodas, kuris surinko skirtingų LLM atsakymus, kad sintezuotų aukštos kokybės atsaką. Tačiau šis metodas pristato esminį įvairovės ir kokybės kompromisą. Nors derinant įvairius modelius, gali suteikti pranašumų, tai taip pat gali sukelti neoptimalų našumą, nes įtraukta žemesnės kokybės atsakai. Tyrėjai siekia subalansuoti šiuos veiksnius, kad užtikrintų optimalų rezultatą nepakenkiant atsakymo kokybei.
Tradiciniai MOA sistemos veikia pirmiausia pateikiant užklausą keliems pasiūlymų teikėjų modeliams, kad būtų galima sugeneruoti atsakymus. Tada kaupiklio modelis sintezuoja šiuos atsakymus į galutinį atsakymą. Šio metodo veiksmingumas remiasi prielaida, kad pasiūlymų teikėjų modelių įvairovė lemia geresnį našumą. Tačiau ši prielaida neatsižvelgia į galimą kokybės blogėjimą, kurį sukelia silpnesni modeliai. Ankstesni tyrimai daugiausia buvo skirti didinti įvairių modelių įvairovę, o ne optimizuoti pasiūlymų teikėjų modelių kokybę, dėl ko atsirado neatitikimai.
Tyrimų komanda iš Prinstono universiteto pristatė naują ansamblio metodą „Self-Moa“, kuris pašalina kelių modelių poreikį, sudedant įvairius rezultatus iš vieno aukšto efektyvumo modelio. Skirtingai nuo tradicinio MOA, kuris maišo skirtingas LLM, „Self-MoA“ panaudoja modelio įvairovę pakartotinai imant iš to paties modelio. Šis požiūris užtikrina, kad tik aukštos kokybės atsakymai prisideda prie galutinės išvesties, nagrinėjant kokybės ir įvairovės kompromisą, stebimą mišrių MOA konfigūracijose.
„Self-MoA“ veikia generuodama kelis atsakymus iš vieno geriausio modelio modelio ir sintezuodama juos į galutinę išvestį. Tai padarius pašalina poreikį įtraukti žemesnės kokybės modelius ir taip pagerinti bendrą atsako kokybę. Norėdami dar labiau padidinti mastelį, tyrėjai pristatė „Self-MoA-Seq“-nuoseklųjį variaciją, kuri pakartotinai apdoroja kelis atsakymus. Tai leidžia efektyviai apibendrinti išėjimus net ir scenarijuose, kuriuose skaičiavimo ištekliai yra suvaržomi. „Self-Moa-Seq“ procesai išėjimai naudojant slenkančio lango metodą, užtikrinant, kad LLM su trumpesniais kontekstiniais ilgiais vis tiek gali būti naudingas ansemencijai, nepakenkiant našumui.
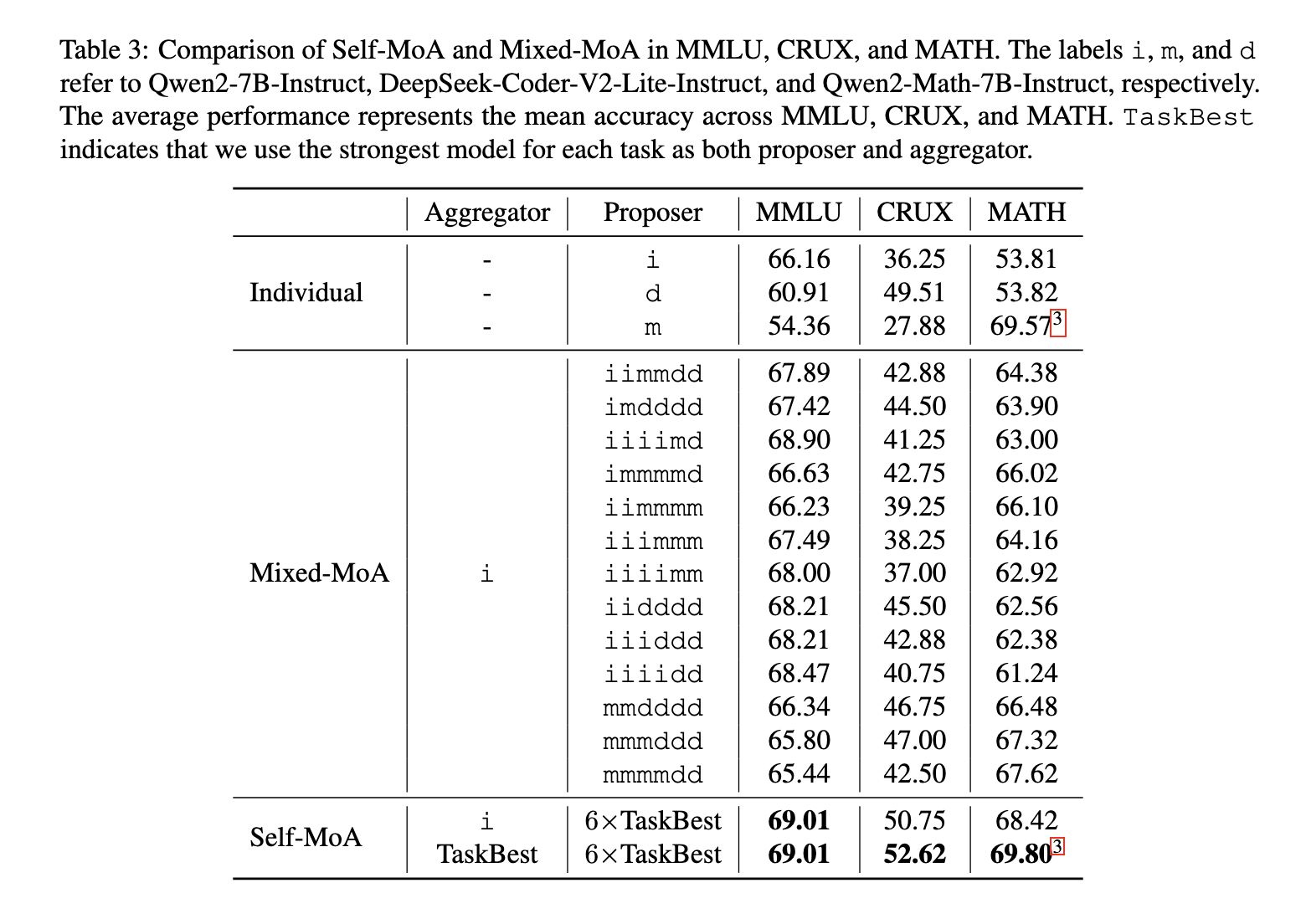
Eksperimentai parodė, kad savi-MOA žymiai pralenkia mišrią Moa įvairiuose etalonuose. „Alpacaeval 2.0“ etalone „Self-Moa“ pagerėjo 6,6%, palyginti su tradiciniu MOA. Testuojant įvairiuose duomenų rinkiniuose, įskaitant MMLU, CRUX ir matematiką, „Self-MoA“ parodė vidutinį 3,8% pagerėjimą, palyginti su mišrių Moa metodais. Taikant vieną iš geriausių „Alpacaeval 2.0“ modelių, „Self-MoA“ nustatė naują moderniausią našumo įrašą, dar labiau patvirtindamas jo efektyvumą. Be to, pasirodė, kad „Self-Moa-Seq“ yra tokia pat veiksminga, kaip vienu metu kaupiant visus rezultatus, tuo pačiu sprendžiant apribojimus, kuriuos nustato modelio konteksto ilgio apribojimai.
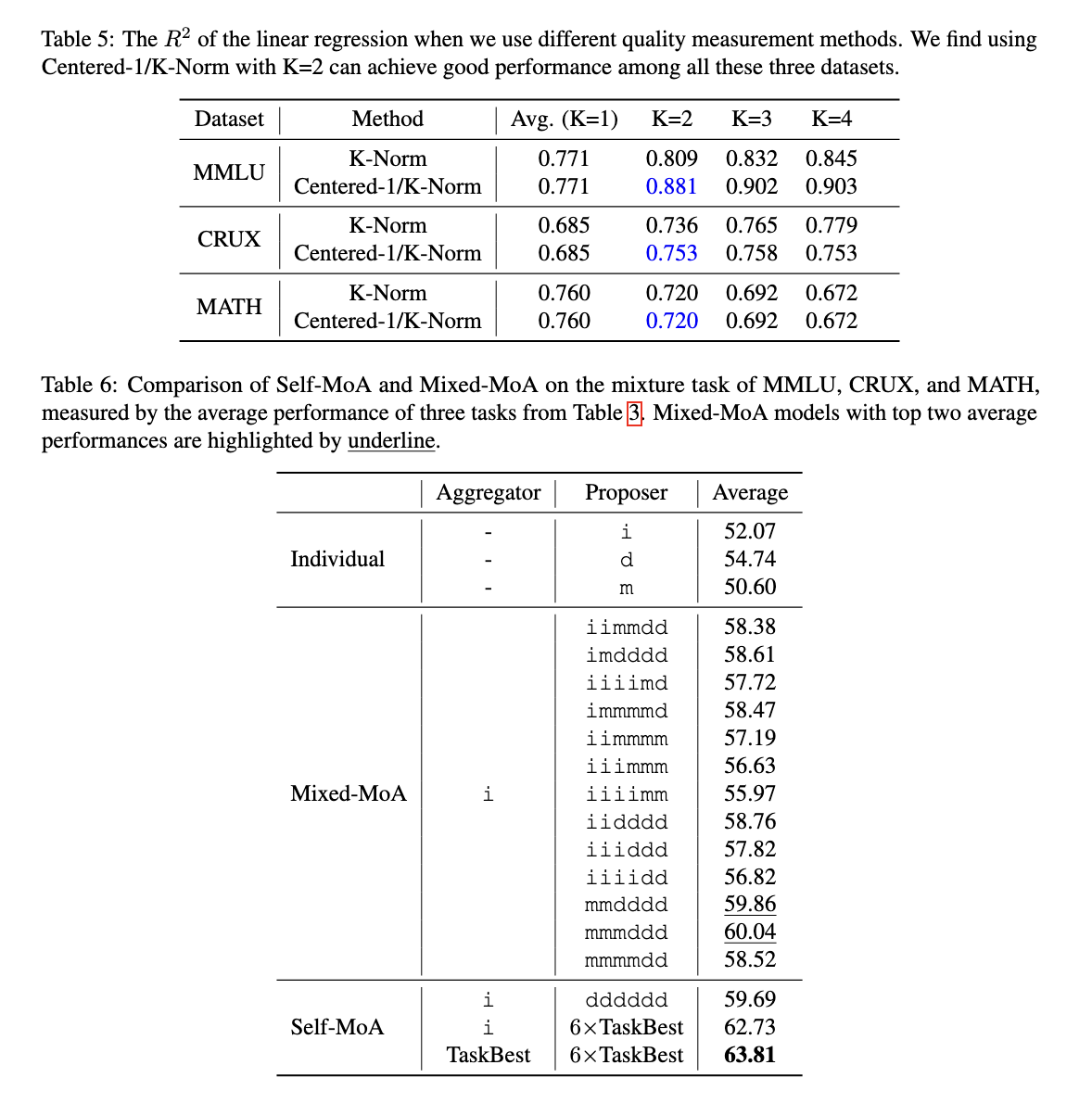
Tyrimo išvados pabrėžia esminę įžvalgą apie MOA konfigūracijas – įgyvendinimas yra labai jautrus pasiūlymo teikėjų kokybei. Rezultatai patvirtina, kad įtraukus įvairius modelius ne visada būna geresni rezultatai. Vietoj to, vienos aukštos kokybės modelio atsakymai duoda geresnių rezultatų. Tyrėjai atliko daugiau nei 200 eksperimentų, norėdami išanalizuoti kokybės ir įvairovės kompromisą, darydami išvadą, kad savaime moa nuosekliai pralenkia mišrią Moa, kai geriausiai veikiantis modelis naudojamas tik kaip pasiūlymo teikėjas.
Šis tyrimas ginčija vyraujančią prielaidą, kad susimaišius su skirtingais LLM, gaunami geresni rezultatai. Parodydamas „Self-Moa“ pranašumą, jis pateikia naują perspektyvą, kaip optimizuoti LLM išvadų laiko skaičiavimą. Rezultatai rodo, kad sutelkti dėmesį į aukštos kokybės atskirus modelius, o ne padidinti įvairovę, gali pagerinti bendrą rezultatą. Toliau tobulėjant LLM tyrimams, „Self-MoA“ suteikia perspektyvią alternatyvą tradiciniams ansamblių metodams, siūlančiai efektyvų ir keičiamą požiūrį į modelio išvesties kokybės gerinimą.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama atvirojo kodo AI platforma: „„ Intellagent “yra atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą“ (Paaukštintas)
Nikhil yra „MarkTechPost“ stažuotės konsultantas. Jis siekia integruoto dvigubo laipsnio medžiagų Indijos technologijos institute, Kharagpur mieste. „Nikhil“ yra AI/ML entuziastas, kuris visada tiria programas tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagos mokslo patirtį, jis tyrinėja naujus pasiekimus ir sukuria galimybes prisidėti.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo





