

Žinių grafikai (KG) yra dirbtinio intelekto programų pagrindas, tačiau jos yra neišsamios ir nedaug, ir tai daro įtaką jų efektyvumui. Nusistovėję KG, tokie kaip dbpedia ir wikidata, trūksta esminių subjektų santykių, mažindami savo naudingumą atkuriant grūdų kartą (RAG) ir kitas mašininio mokymosi užduotis. Tikėtina, kad tradiciniai ištraukimo metodai pateiks nedidelius grafikus, kuriuose nėra svarbių jungčių ar triukšmingų, nereikalingų atvaizdų. Todėl iš nestruktūrizuoto teksto sunku įgyti aukštos kokybės struktūrizuotų žinių. Šių iššūkių įveikimas yra labai svarbus, kad būtų galima patobulinti žinių gavimą, samprotavimus ir įžvalgas padedant dirbtiniam intelektui.
Šiuolaikiški KG išgavimo metodai iš neapdoroto teksto yra „Open Information Extraction“ (Openie) ir „GraphRag“. „Openie“, priklausomybės analizės technika, sukuria struktūrizuotą (temą, santykį, objektą) trigubai, tačiau sukuria ypač sudėtingus ir nereikalingus mazgus, mažindama darną. „GraphRag“, kuriame derinami grafiko gavimo ir kalbos modeliai, sustiprina subjektų susiejimą, tačiau nesukuria tankiai sujungtų grafikų, ribodamas pasroviui pagrįstų procesus. Abu metodus kenčia nuo mažo subjekto skiriamosios gebos nuoseklumo, jungiamumo ir prasto apibendrinamumo, todėl jie neveiksmingi aukštos kokybės kg ekstrahavimui.
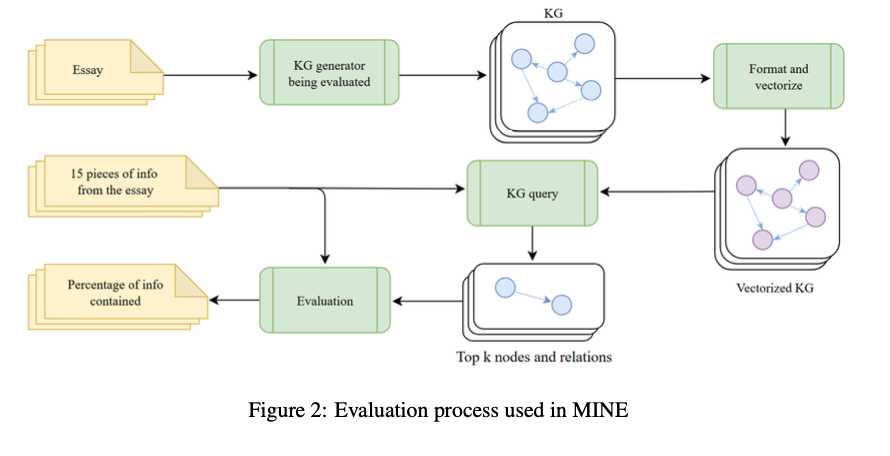
Tyrėjai iš Stanfordo universiteto, Toronto universiteto ir „Far AI“ pristato naują teksto „teksto iki kg“ generatorių, kuris panaudoja kalbų modelius ir grupavimo algoritmus, kad iš paprasto teksto išgautų struktūrizuotas žinias. Skirtingai nuo ankstesnių metodų, „Kggen“ pristato iteracinį LM pagrįstą grupavimo metodą, kuris sustiprina ištrauktą grafiką sujungdamas sinoniminius subjektus ir grupių ryšius. Tai sustiprina raumenis ir atleidimą, siūlant dar labiau sujungtą ir gerai sujungtą KG. „Kggen“ taip pat pristato kasyklą (informacijos matavimas mazguose ir kraštuose)-tai pirmasis etalonas, skirtas ekstrahavimo tekstui iki kg eksploatacinėms savybėms, įgalindamas standartizuotus ekstrahavimo metodų matavimo metodus.
„Kggen“ veikia per modulinį „Python“ paketą su subjekto moduliais ir santykių ištraukimu, agregacija ir subjektu bei kraštų grupavimu. Subjekto ir santykių ištraukimo modulyje naudojamas GPT-4O, kad būtų gautas struktūrizuotas trigubas (subjektas, predikatas, objektas) iš nestruktūrizuoto teksto. Apibendrinimo modulis sujungia iš skirtingų šaltinių ištrauktus trigubus į vieningą žinių grafiką (kg), taigi užtikrina vienalytį subjektų vaizdavimą. Entity ir Edge grupavimo modulis naudoja pasikartojantį klasterizacijos algoritmą, kad būtų galima išsiaiškinti sinoniminius subjektus, grupuoti panašius kraštus ir sustiprinti grafiko ryšį. Vykdydamas griežtus kalbos modelio apribojimus, naudojant DSPY, „Kggen“ leidžia pasiekti struktūrizuotą ir didelį išsamią ekstrakciją. Išėjimo žinių grafikas išsiskiria iš tankaus ryšio, semantinio aktualumo ir optimizavimo dirbtinio intelekto tikslais.
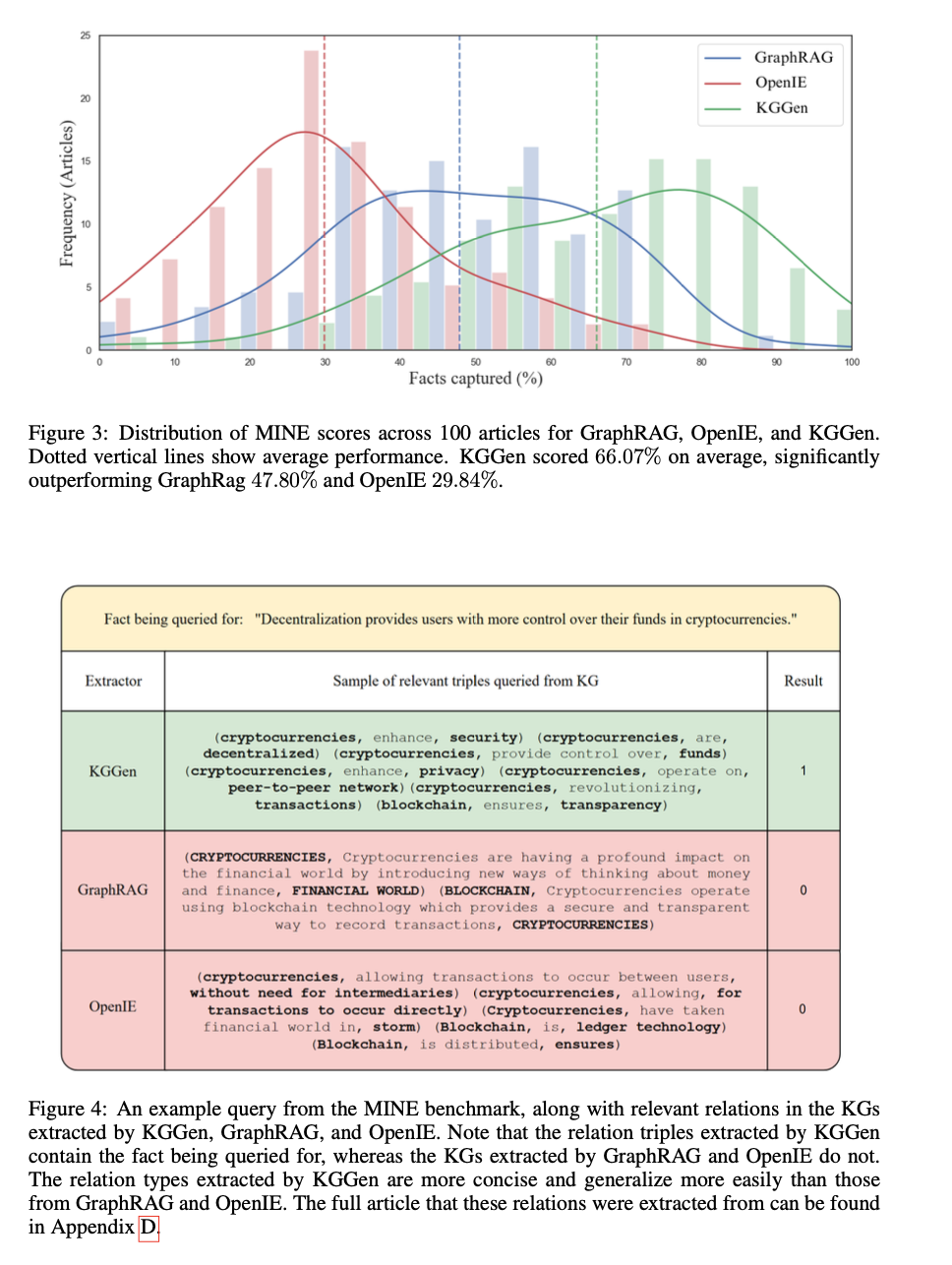
Lyginamosios analizės rezultatai rodo metodo sėkmę ištraukiant struktūrizuotas žinias iš teksto šaltinių. Kggenas gauna 66,07%tikslumo greitį, tai yra žymiai didesnis nei „Graphrag“, esant 47,80%, o „Openie“ – 29,84%. Sistema palengvina galimybes išgauti ir struktūruoti žinias be atleidimo iš darbo ir sustiprinti ryšį ir darną. Lyginamoji analizė patvirtina 18% ištikimo ištikimybės pagerėjimą, palyginti su esamais metodais, pabrėžiant jo sugebėjimą sudaryti gerai struktūruotus žinių grafikus. Testai taip pat parodo, kad sukurti grafikai yra tankesni ir informatyvesni, todėl jie yra ypač tinkami atliekant žinių gavimo užduotis ir AI pagrįstus samprotavimus.
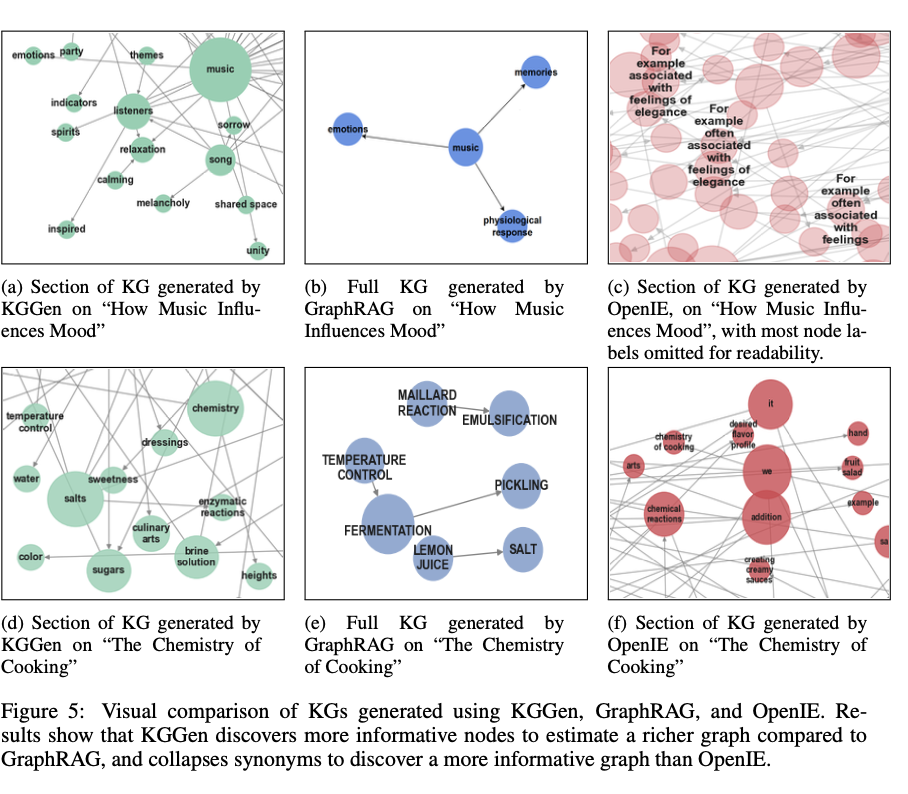
„KGGEN“ yra žinių grafiko ištraukimo lauko proveržis, nes jis suporuoja kalbų modelius pagrįstą subjektų atpažinimą su iteraciniais grupavimo metodais, kad būtų sukurta aukštesnės kokybės struktūrizuoti duomenys. Pasiekdamas radikaliai pagerėjusį minų etalono tikslumą, jis iškelia juostą, kad nestruktūrizuotas tekstas būtų paverčiamas poveikio reprezentacijomis. Šis proveržis turi didelę įtaką dirbtinio intelekto pagrįstų žinių gavimo, samprotavimo operacijų ir mokymosi įterpimui, taip sudarant kelią tolesniam didesnių ir išsamesnių žinių grafikų plėtrai. Ateities plėtra sutelks dėmesį į klasterizacijos metodų tobulinimą ir etaloninių bandymų išplėtimą, kad būtų galima aprėpti didesnius duomenų rinkinius.
Patikrinkite popierius. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Taip pat nedvejodami sekite mus „Twitter“ Ir nepamirškite prisijungti prie mūsų 75K+ ml subreddit.
🚨 Rekomenduojama „Read-LG AI Research“ išleidžia „Nexus“: pažangių sistemos integracinių agentų AI sistemos ir duomenų atitikties standartų, skirtų teisiniams klausimams spręsti AI duomenų rinkiniuose
Aswinas AK yra „MarktechPost“ konsultavimo praktikantas. Jis siekia dvigubo laipsnio Indijos technologijos institute Kharagpur. Jis aistringai vertina duomenų mokslą ir mašininį mokymąsi, sukelia stiprią akademinę patirtį ir praktinę patirtį sprendžiant realaus gyvenimo įvairių sričių iššūkius.







