Didelės kalbos modeliai (LLM) tapo būtini įvairioms natūralios kalbos apdorojimo programoms, įskaitant mašininį vertimą, teksto apibendrinimą ir pokalbio AI. Tačiau didėjantis jų sudėtingumas ir dydis sukėlė reikšmingų skaičiavimo efektyvumo ir atminties sunaudojimo iššūkių. Augant šiems modeliams, išteklių paklausa juos sunku diegti aplinkoje, kurioje yra ribotos skaičiavimo galimybės.
Pagrindinė kliūtis, susijusi su LLMS, yra jų didžiuliai skaičiavimo reikalavimai. Šių modelių mokymas ir patobulinimas apima milijardus parametrų, todėl jie yra daug išteklių ir riboja jų prieinamumą. Esami efektyvumo gerinimo metodai, tokie kaip parametrą efektyvus derinimas (PEFT), suteikia tam tikrą reljefą, tačiau dažnai kompromisus našumas. Iššūkis yra rasti požiūrį, kuris galėtų žymiai sumažinti skaičiavimo reikalavimus, išlaikant modelio tikslumą ir efektyvumą realaus pasaulio scenarijuose. Tyrėjai tyrinėjo metodus, leidžiančius efektyviai suderinti modelį, nereikalaujant didelių skaičiavimo išteklių.
„Intel Labs“ ir „Intel Corporation“ tyrėjai pristatė metodą, integruojantį žemo rango adaptacijos (LORA) su nervų architektūros paieškos (NAS) metodais. Šiuo metodu siekiama išspręsti tradicinių tikslinimo metodų apribojimus, tuo pačiu padidinant efektyvumą ir našumą. Tyrimo komanda sukūrė sistemą, kuri optimizuoja atminties sunaudojimą ir skaičiavimo greitį, pasinaudodama struktūrizuotomis žemo rango vaizdais. Ši technika apima svorio dalijimosi super tinklą, kuris dinamiškai sureguliuoja substruktūras, kad padidintų treniruočių efektyvumą. Ši integracija leidžia modeliui efektyviai suderinti, išlaikant minimalų skaičiavimo pėdsaką.
„Intel Labs“ įvesta metodika yra sutelkta į LONAS (žemos rango nervų architektūros paieška), kurioje naudojami elastiniai LORA adapteriai, skirti modeliui suderinti. Skirtingai nuo įprastų metodų, kuriems reikia visiškai tiksliai suderinti LLM, LONAS leidžia selektyviai suaktyvinti modelio substruktūras, mažinant perteklių. Pagrindinė naujovė yra elastinių adapterių lankstumas, kuris dinamiškai koreguoja pagal modelio reikalavimus. Šį požiūrį palaiko euristiniai sub-tinklų paieškos, kurios dar labiau supaprastins tikslinimo procesą. Daugiausia dėmesio skiriant tik atitinkamiems modelio parametrams, ši technika pasiekia pusiausvyrą tarp skaičiavimo efektyvumo ir našumo. Procesas yra sudarytas taip, kad būtų galima selektyviai suaktyvinti žemo rango struktūras, išlaikant didelį išvadų greitį.
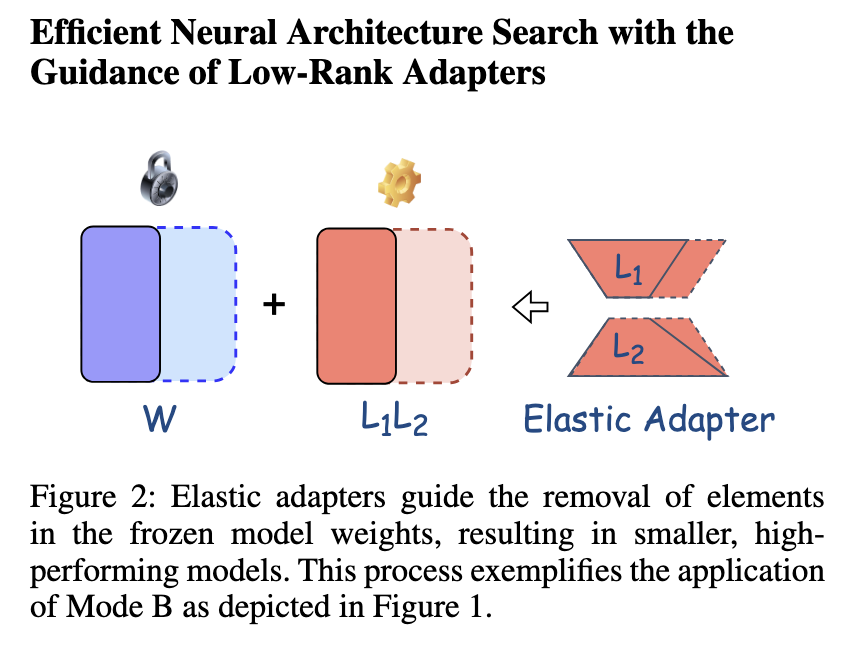
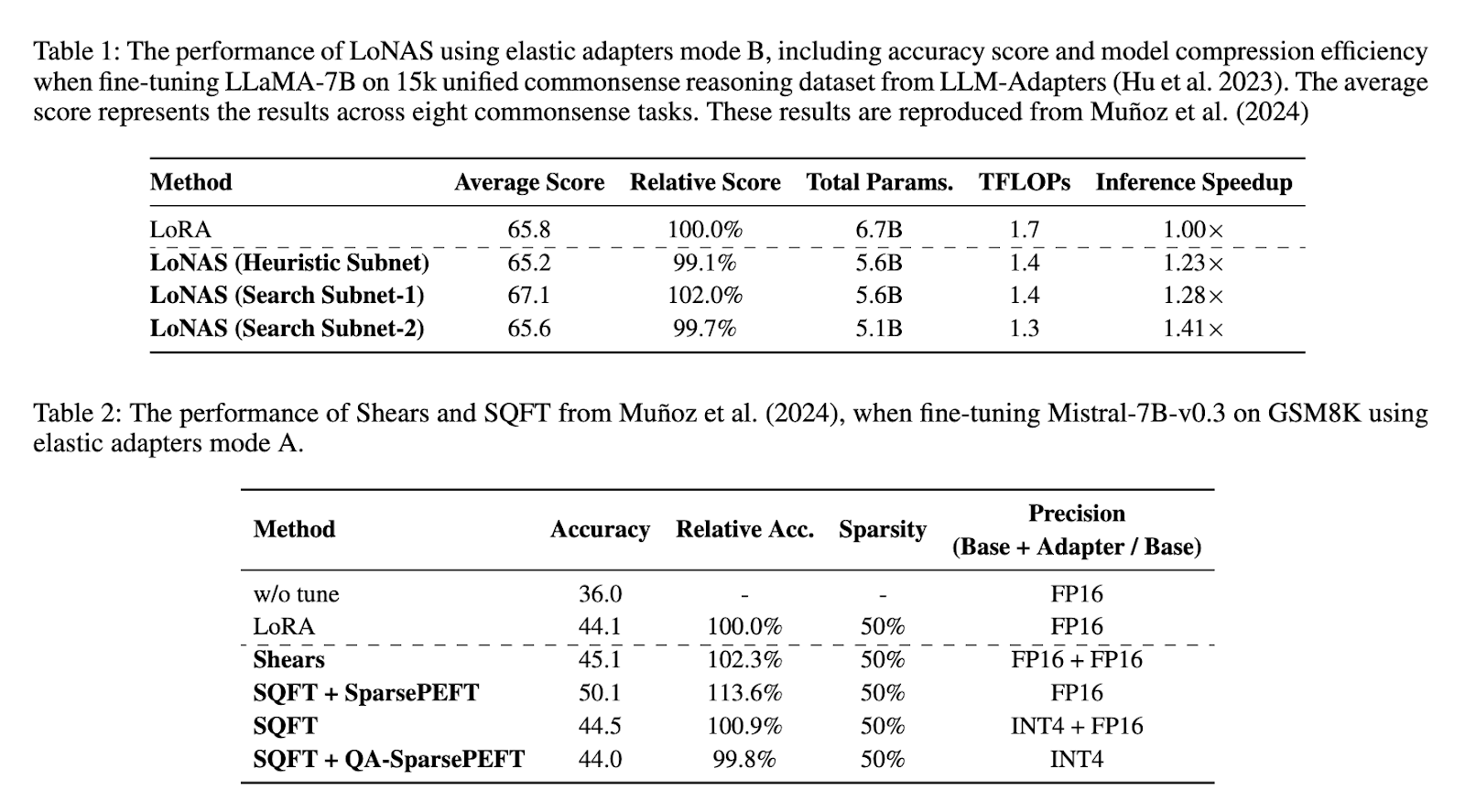
Siūlomo metodo veiklos įvertinimas pabrėžia reikšmingus jo patobulinimus, palyginti su įprastiniais metodais. Eksperimentiniai rezultatai rodo, kad LONA padidina išvadų greitį iki 1,4x, tuo pačiu sumažindamas modelio parametrus maždaug 80%. Taikant „LlaM-7B“ tobulinant 15K vieningą bendrojo pagrindimo duomenų rinkinį, LONAS parodė, kad vidutinis tikslumo balas buvo 65,8%. Lyginamoji skirtingų LONAS konfigūracijų analizė parodė, kad euristinis potinklio optimizavimas pasiekė 1,23x greitį, o paieškos potinklio konfigūracijose – 1,28x ir 1,41x. Be to, „Mistral-7b-V0.3“ pritaikymas LONA atliekant GSM8K užduotis padidino tikslumą nuo 44,1% iki 50,1%, išlaikant efektyvumą skirtinguose modelio dydžiuose. Šios išvados patvirtina, kad siūloma metodika žymiai pagerina LLM veikimą ir sumažina skaičiavimo reikalavimus.
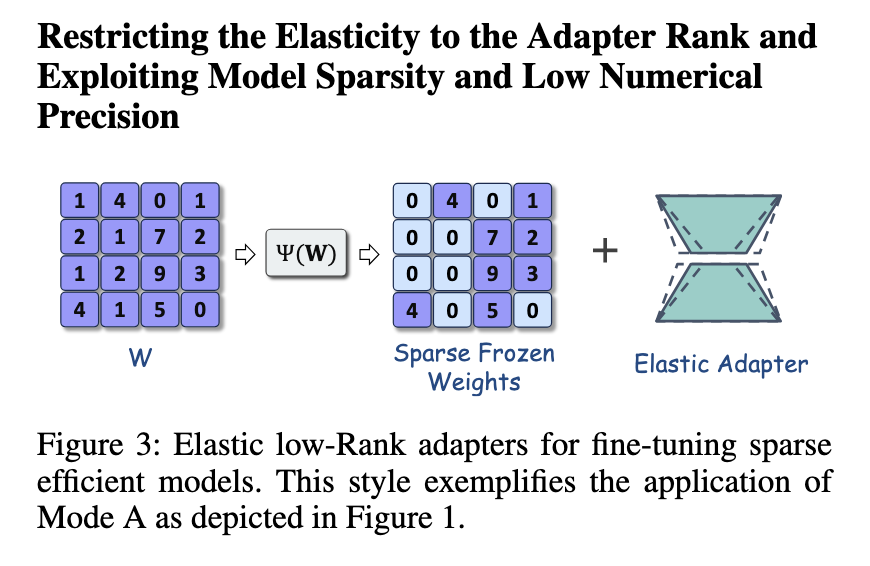
Tolesni sistemos patobulinimai apima „Shears“ įvedimą, pažangią tobulinimo strategiją, kuria remiasi LONA. Žirgos naudoja nervų žemo rango adapterio paiešką (NLS), kad apribotų elastingumą iki adapterio reitingo, sumažinant nereikalingus skaičiavimus. Šis metodas taikomas baziniam modeliui, naudojant iš anksto nustatytą metriką, užtikrinant, kad tobulinimas išliktų efektyvus. Ši strategija buvo ypač veiksminga palaikant modelio tikslumą, tuo pačiu sumažinant aktyvių parametrų skaičių. Kitas pratęsimas „SQFT“ apima rašomumą ir žemą skaitinį tikslumą, kad būtų patobulintas tobulinamas derinimas. Naudodamas kvantizavimo metodus, „SQFT“ užtikrina, kad nedaug modelių gali būti tiksliai sureguliuojami neprarandant efektyvumo. Šie patobulinimai pabrėžia LONAS pritaikomumą ir jo galimybes tolesniam optimizavimui.
„Lora“ ir NAS integravimas siūlo transformacinį požiūrį į didelio kalbos modelio optimizavimą. Pasitelkdami struktūrizuotus žemo rango reprezentacijas, tyrimas rodo, kad skaičiavimo efektyvumą galima žymiai pagerinti nepakenkiant veiklai. „Intel Labs“ atliktas tyrimas patvirtina, kad derinant šiuos metodus sumažinama tikslinimo našta, užtikrinant modelio vientisumą. Būsimi tyrimai galėtų ištirti tolesnį optimizavimą, įskaitant patobulintą potvynių pasirinkimą ir efektyvesnes euristikos strategijas. Šis metodas sukuria precedentą, kad LLM būtų prieinamesni ir dislokuojami įvairiose aplinkose, sudarydamas kelią efektyvesniems AI modeliams.
Patikrinkite Popieriaus ir „GitHub“ puslapis. Visas šio tyrimo kreditas skirtas šio projekto tyrėjams. Be to, nepamirškite sekti mūsų „Twitter“ ir prisijunkite prie mūsų „Telegram“ kanalas ir „LinkedIn GrOUP. Nepamirškite prisijungti prie mūsų 70K+ ml subreddit.
🚨 Susipažinkite su „Intellagent“: atvirojo kodo daugialypės terpės sistema, skirta įvertinti sudėtingą pokalbio AI sistemą (Paaukštintas)
Nikhil yra „MarkTechPost“ stažuotės konsultantas. Jis siekia integruoto dvigubo laipsnio medžiagų Indijos technologijos institute, Kharagpur mieste. „Nikhil“ yra AI/ML entuziastas, kuris visada tiria programas tokiose srityse kaip biomedžiagos ir biomedicinos mokslas. Turėdamas tvirtą medžiagos mokslo patirtį, jis tyrinėja naujus pasiekimus ir sukuria galimybes prisidėti.
✅ (rekomenduojama) Prisijunkite prie mūsų telegramos kanalo