
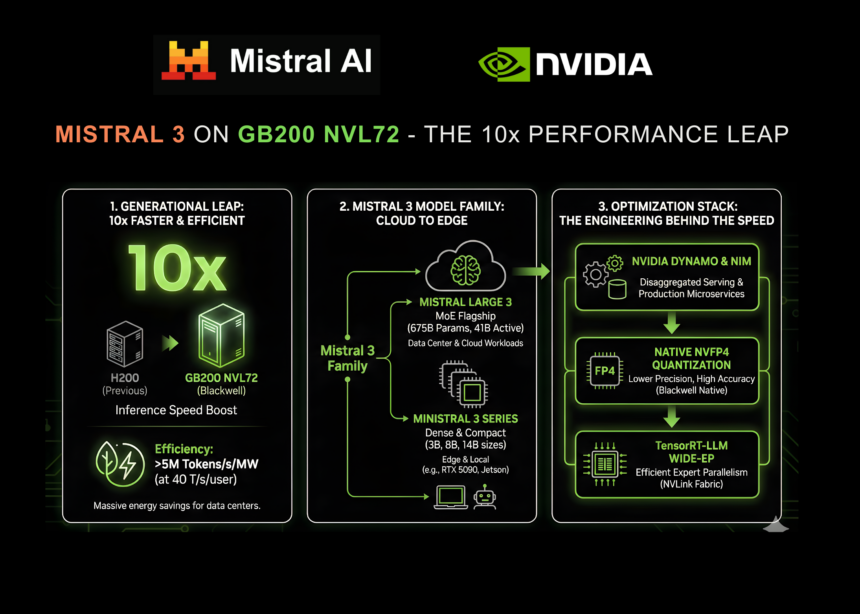
NVIDIA šiandien paskelbė reikšmingai išplėtusi savo strateginį bendradarbiavimą su „Mistral AI“. Ši partnerystė sutampa su naujosios „Mistral 3 Frontier Open“ modelių šeimos išleidimu, pažymint esminį momentą, kai aparatinės įrangos spartinimas ir atvirojo kodo modelio architektūra susiliejo, kad iš naujo apibrėžtų našumo etalonus.
Šis bendradarbiavimas yra didžiulis išvadų greičio šuolis: nauji modeliai dabar veikia 10 kartų greitesnis NVIDIA GB200 NVL72 sistemose palyginti su ankstesnės kartos H200 sistemomis. Šis proveržis atskleidžia precedento neturintį įmonės lygio AI efektyvumą, žadėdamas išspręsti delsos ir išlaidų kliūtis, kurios istoriškai kankino plataus masto samprotavimo modelių diegimą.
Kartų šuolis: 10 kartų greičiau Blackwell
Kadangi įmonės paklausa pereina nuo paprastų pokalbių robotų prie rimtų, ilgo konteksto agentų, išvadų efektyvumas tapo kritine kliūtimi. NVIDIA ir „Mistral AI“ bendradarbiavimas išsprendžia šią problemą optimizuodamas „Mistral 3“ šeimą specialiai NVIDIA Blackwell architektūrai.
Jei gamybinės dirbtinio intelekto sistemos turi užtikrinti gerą vartotojo patirtį (UX) ir ekonomišką mastą, NVIDIA GB200 NVL72 užtikrina iki 10 kartų didesnį našumą nei ankstesnės kartos H200. Tai ne tik neapdoroto greičio padidėjimas; tai reiškia žymiai didesnį energijos vartojimo efektyvumą. Sistema viršija 5 000 000 žetonų per sekundę vienam megavatui (MW) esant 40 žetonų per sekundę vartotojų interaktyvumo greičiui.
Duomenų centrams, susiduriantiems su energijos apribojimais, šis efektyvumo padidėjimas yra toks pat svarbus kaip ir pats našumo padidėjimas. Šis kartos šuolis užtikrina mažesnes sąnaudas už žetoną, kartu išlaikant didelį pralaidumą, reikalingą realiojo laiko programoms.
Nauja Mistral 3 šeima
Šį našumą varantis variklis yra naujai išleista Mistral 3 šeima. Šis modelių rinkinys suteikia pramonėje pirmaujančią tikslumą, efektyvumą ir pritaikymo galimybes, apimančias spektrą nuo didžiulio duomenų centro darbo krūvio iki galutinio įrenginio išvadų.
„Mistral Large 3“: pavyzdinis AM
Hierarchijos viršuje yra „Mistral Large 3“ – modernus negausus daugiarūšio ir daugiakalbio ekspertų mišinio (MoE) modelis.
- Bendri parametrai: 675 mlrd
- Aktyvūs parametrai: 41 mlrd
- Kontekstinis langas: 256 tūkst. žetonų
Mokytas naudoti NVIDIA Hopper GPU, „Mistral Large 3“ sukurtas sudėtingoms samprotavimo užduotims atlikti, siūlydamas lygiavertiškumą su aukščiausios klasės uždarais modeliais, išlaikant atvirų svorių lankstumą.
Ministras 3: tanki galia pakraštyje
Didelį modelį papildo Ministerijos 3 serija – mažų, tankių, didelio našumo modelių rinkinys, sukurtas greitumui ir universalumui.
- Dydžiai: 3B, 8B ir 14B parametrus.
- Variantai: Kiekvieno dydžio pagrindas, nurodymas ir samprotavimas (iš viso devyni modeliai).
- Kontekstinis langas: 256 tūkst. žetonų.
The Ministerijos 3 serija pasižymi GPQA Diamond Accuracy etalonu, naudodama 100 mažiau žetonų, o pristatydama didesnį tikslumą:

Didelė inžinerija už greičio: visapusiškas optimizavimo krūvas
„10 kartų“ našumo teiginį lemia daugybė optimizacijų, kurias kartu sukūrė „Mistral“ ir NVIDIA inžinieriai. Komandos taikė „ypatingo bendro projektavimo“ metodą, sujungdamos aparatinės įrangos galimybes su modelio architektūros koregavimais.
TensorRT-LLM Wide Expert Parallelism (Wide-EP)
Siekdama visiškai išnaudoti didžiulį GB200 NVL72 mastą, NVIDIA TensorRT-LLM naudojo platų ekspertų paraleliškumą. Ši technologija suteikia optimizuotus MoE GroupGEMM branduolius, ekspertų platinimą ir apkrovos balansavimą.
Svarbiausia, kad „Wide-EP“ išnaudoja NVL72 nuoseklią atminties sritį ir „NVLink“ audinį. Jis yra labai atsparus architektūriniams skirtumams didelėse Ūkio ministerijose. Pavyzdžiui, „Mistral Large 3“ kiekviename sluoksnyje naudoja maždaug 128 ekspertus, maždaug perpus mažiau nei panašiuose modeliuose, tokiuose kaip „DeepSeek-R1“. Nepaisant šio skirtumo, „Wide-EP“ leidžia modeliui realizuoti didelio pralaidumo, mažo vėlavimo ir neblokuojančius „NVLink“ audinio pranašumus, užtikrinant, kad didžiulis modelio dydis nesukels ryšio kliūčių.
Vietinis NVFP4 kvantavimas
Vienas iš svarbiausių techninių patobulinimų šioje laidoje yra NVFP4, kvantavimo formato, būdingo Blackwell architektūrai, palaikymas.
„Mistral Large 3“ kūrėjai gali įdiegti skaičiavimams optimizuotą NVFP4 kontrolinį tašką, kvantuojamą neprisijungus, naudodami atvirojo kodo llm-kompresoriaus biblioteką.
Šis metodas sumažina skaičiavimo ir atminties sąnaudas, kartu griežtai išlaikant tikslumą. Jis naudoja NVFP4 didesnio tikslumo FP8 mastelio koeficientus ir smulkesnį bloko mastelį, kad kontroliuotų kvantavimo klaidą. Receptas konkrečiai skirtas MoE svoriams, kartu išlaikant kitų komponentų pradinį tikslumą, leidžiantį modelį sklandžiai naudoti GB200 NVL72, mažinant tikslumą.
Išskaidytas aptarnavimas naudojant „NVIDIA Dynamo“.
„Mistral Large 3“ naudoja NVIDIA Dynamo, mažos delsos paskirstytų išvadų sistemą, kad išskaidytų išankstinio užpildymo ir iššifravimo išvados fazes.
Įprastose sąrankose išankstinio užpildymo fazė (apdoroja įvesties raginimą) ir dekodavimo fazė (generuoja išvestį) konkuruoja dėl išteklių. Suderindama ir išskaidydama šias fazes, „Dinamo“ žymiai padidina ilgo konteksto darbo krūvių, pvz., 8K įvesties / 1K išvesties konfigūracijų, našumą. Tai užtikrina didelį pralaidumą net naudojant didžiulį modelio 256K konteksto langą.
Nuo debesies iki krašto: Ministral 3 pasirodymas
Optimizavimo pastangos apima ne tik didžiulius duomenų centrus. Pripažįstant augantį vietinio dirbtinio intelekto poreikį, Ministral 3 serija yra sukurta taip, kad būtų galima naudoti kraštutiniu mastu, todėl siūlo lankstumą įvairiems poreikiams patenkinti.
RTX ir Jetson Acceleration
Tankūs Ministrų modeliai yra optimizuoti tokioms platformoms kaip NVIDIA GeForce RTX AI PC ir NVIDIA Jetson robotikos moduliai.
- RTX 5090: Ministral-3B variantai gali pasiekti puikų išvadų greitį 385 žetonai per sekundę NVIDIA RTX 5090 GPU. Tai vietiniams kompiuteriams suteikia darbo stočių klasės AI našumą, leidžia greitai iteruoti ir užtikrinti didesnį duomenų privatumą.
- Jetsonas Thoras: Robotikai ir krašto AI kūrėjai gali naudoti vLLM konteinerį NVIDIA Jetson Thor. Ministral-3-3B-Instruct modelis pasiekia 52 žetonus per sekundę vienu lygiagrečiai, padidindamas iki 273 žetonai per sekundę su 8 vienu metu.
Platus pagrindų palaikymas
NVIDIA bendradarbiavo su atvirojo kodo bendruomene, siekdama užtikrinti, kad šie modeliai būtų naudojami visur.
- Llama.cpp ir Ollama: NVIDIA bendradarbiavo su šiomis populiariomis sistemomis, kad užtikrintų greitesnę iteraciją ir mažesnį vietinės plėtros delsą.
- SGLang: NVIDIA bendradarbiavo su SGLang, kad sukurtų Mistral Large 3 įgyvendinimą, kuris palaiko ir išskaidymą, ir spekuliacinį dekodavimą.
- vLLM: NVIDIA bendradarbiavo su vLLM, siekdama išplėsti branduolio integracijų palaikymą, įskaitant spekuliacinį dekodavimą (EAGLE), Blackwell palaikymą ir išplėstą lygiagretumą.
Paruošta gamybai naudojant NVIDIA NIM
Siekiant supaprastinti įmonės pritaikymą, nauji modeliai bus prieinami per NVIDIA NIM mikropaslaugos.
„Mistral Large 3“ ir „Ministral-14B-Instruct“ šiuo metu pasiekiami per NVIDIA API katalogą ir peržiūros API. Netrukus įmonių kūrėjai galės naudotis atsisiunčiamomis NVIDIA NIM mikropaslaugomis. Tai yra konteinerinis, gamybai paruoštas sprendimas, leidžiantis įmonėms įdiegti „Mistral 3“ šeimą su minimalia sąranka bet kurioje GPU pagreitintoje infrastruktūroje.
Šis prieinamumas užtikrina, kad specifinis GB200 NVL72 „10x“ našumo pranašumas gali būti įgyvendintas gamybinėje aplinkoje be sudėtingos individualios inžinerijos, demokratizuojant prieigą prie aukščiausios klasės intelekto.
Išvada: naujas atvirojo intelekto standartas
NVIDIA pagreitinto Mistral 3 atvirojo modelio šeimos išleidimas yra didelis DI šuolis atvirojo kodo bendruomenėje. Siūlydami aukščiausio lygio našumą pagal atvirojo kodo licenciją ir palaikydami tvirtą aparatinės įrangos optimizavimo rinkinį, „Mistral“ ir „NVIDIA“ susitinka su kūrėjais ten, kur jie yra.
Nuo didžiulio GB200 NVL72 masto, kuriame naudojamas „Wide-EP“ ir NVFP4, iki „Ministral“ tankio RTX 5090, ši partnerystė yra keičiamo dydžio, efektyvus dirbtinio intelekto kelias. Tikimasi, kad dėl būsimų optimizacijų, tokių kaip spekuliacinis dekodavimas su kelių ženklų numatymu (MTP) ir EAGLE-3, našumas dar labiau padidės, Mistral 3 šeima yra pasirengusi tapti pagrindiniu naujos kartos AI programų elementu.
Galima išbandyti!
Jei esate kūrėjas, norintis palyginti šį našumo padidėjimą, galite atsisiųsti „Mistral 3“ modelius tiesiai iš „Hugging Face“ arba išbandyti nediegimo priglobtas versijas adresu build.nvidia.com/mistralai, kad įvertintumėte delsą ir pralaidumą jūsų konkrečiam naudojimo atvejui.
Peržiūrėkite modelius Apkabinantis Veidas. Išsamią informaciją galite rasti adresu Įmonės tinklaraštis ir Technikos / kūrėjų tinklaraštis.
Dėkojame NVIDIA AI komandai už vadovavimą mintims / išteklius už šį straipsnį. NVIDIA AI komanda palaikė šį turinį / straipsnį.

Jean-Marc yra sėkmingas dirbtinio intelekto verslo vadovas. Jis vadovauja ir spartina dirbtinio intelekto sprendimų augimą ir 2006 m. įkūrė kompiuterinės vizijos įmonę. Jis yra pripažintas DI konferencijų pranešėjas ir Stanfordo magistrantūros studijas.
🙌 Sekite MARKTECHPOST: pridėkite mus kaip pageidaujamą „Google“ šaltinį.





